
Kafka Connect, part of the Apache Kafka project, is a development framework and runtime for connectors which either ingest data into Kafka clusters (source connectors) or propagate data from Kafka into external systems (sink connectors). A diverse ecosystem of ready-made connectors has come to life on top of Kafka Connect, which lets you connect all kinds of data stores, APIs, and other systems to Kafka in a no-code approach.
With the continued move towards running software in the cloud and on Kubernetes in particular, it’s just natural that many folks also try to run Kafka Connect on Kubernetes. On first thought, this should be simple enough: just take the Connect binary and some connector(s), put them into a container image, and schedule it for execution on Kubernetes. As so often, the devil is in the details though: should you use Connect’s standalone or distributed mode? How can you control the lifecycle of specific connectors via the Kubernetes control plane? How to make sure different connectors don’t compete unfairly on resources such as CPU, RAM, or network bandwidth? In the remainder of this blog post, I’d like to explore running Kafka Connect on Kubernetes, what some of the challenges are for doing so, and how Kafka Connect could potentially be reimagined to become more "Kubernetes-friendly" in the future.
Standalone or Distributed?
If you’ve used Kafka Connect before, then you’ll know that it has two modes of execution: standalone and distributed. In the former, you configure Connect via property files which you pass as parameters during launch. There will be a single process which executes all the configured connectors and their tasks. In distributed mode, multiple Kafka Connect worker nodes running on different machines form a cluster onto which the workload of the connectors and their tasks is distributed. Configuration is done via a REST API which is exposed on all the worker nodes. Internally, A Connect-specific protocol (which itself is based on Kafka’s group membership protocol) is used for the purposes of coordination and task assignment.
The distributed mode is in general the preferred and recommended mode of operating Connect in production, due to its obvious advantages in regards to scalability (one connector can spawn many tasks which are executed on different machines), reliability (connector configuration and offset state is stored in Kafka topics rather than files in the local file system), and fault tolerance (if one worker node crashes, the tasks which were scheduled on that node can be transparently rebalanced to other members of the Connect cluster).
That’s why also Kafka users on Kubernetes typically opt for Connect’s distributed mode, as for instance it’s the case with Strimzi’s operator for Kafka Connect. But that’s not without its issues either, as now essentially two scheduling systems are competing with each other: Kubernetes itself (scheduling pods to compute nodes), and Connect’s worker coordination mechanism (scheduling connector tasks to Connect worker nodes). This becomes particularly apparent in case of node failures. Should the Kubernetes scheduler spin up the affected pods on another node in the Kubernetes cluster, or should you rely on Connect to schedule the affected tasks to another Connect worker node? Granted, improvements in this area have been made, for instance in form of Kafka improvement proposal KIP-415 ("Incremental Cooperative Rebalancing in Kafka Connect"). It adds a new configuration property scheduled.rebalance.max.delay.ms, allowing you to defer rebalances after worker failures. But such a setting will always be a trade-off, and I think in general it’s fair to say that if there’s multiple components in a system which share the same responsibility (placement of workloads), that’s likely going to be a friction point.
Issues with Kafka Connect on Kubernetes
So let’s explore a bit more the challenges users often encounter when running Kafka Connect on Kubernetes. One general problem is the lack of awareness for running on Kubernetes from a Connect perspective.
For instance, consider the case of a stretched Kubernetes cluster, with Kubernetes nodes running in different regions of a cloud provider, or within different data centers. Let’s assume you have a source connector which ingests data from a database running within one of the regions. As you’re only interested in a subset of the records produced by that connector, you use a Kafka Connect single message transformation for filtering out a significant number of records. In that scenario, it makes sense to deploy that connector in local proximity to the database it connects to, so as to limit the data that’s transferred across network boundaries. But Kafka Connect doesn’t have any understanding of "regions" or related Kubernetes concepts like node selectors or node pools, i.e. you’ll lack the control needed for making sure that the tasks of that connector get scheduled onto Connect worker nodes running on the right Kubernetes nodes (a mitigation strategy would be to set up multiple Connect clusters, tied to specific Kubernetes node pools in the different regions).
A second big source of issues is Connect’s model for the deployment of connectors, which in a way resembles the approach taken by Java application servers in the past: multiple, independent connectors are deployed and executed in shared JVM processes. This results in a lack of isolation between connectors, which can have far-reaching consequences in production scenarios:
-
Connectors compete on resources: one connector or task can use up an unfairly large share of CPU, RAM or networking resources assigned to a pod, so that other connectors running on the same Connect worker will be negatively impacted; this could be caused by bugs or poor programming, but it also can simply be a result of different workload requirements, with one connector requiring more resources than others. While a rate limiting feature for Connect is being proposed via KIP-731 (which may eventually address the issue of distributing network resources more fairly), there’s no satisfying answer for assigning and limiting CPU and RAM resources when running multiple connectors on one shared JVM, due to its lack of application isolation.
-
Scaling complexities: when increasing the number of tasks of a connector (so as to scale out its load), it’s likely also necessary to increase the number of Connect workers, unless there were idle workers before; this process seems more complex and at the same time less powerful than it should be. For instance, there’s no way for ensuring that additional worker nodes would exclusively be used for the tasks of one particularly demanding connector.
-
Security implications: as per the OpenJDK Vulnerability Group, "speculative execution vulnerabilities (e.g., Meltdown, Spectre, and RowHammer) cannot be addressed in the JDK. These hardware design flaws make complete intra-process isolation impossible". Malicious connectors could leverage these attack vectors for instance to obtain secrets from other connectors running on the same JVM. Furthermore, some connectors rely on secrets (such as cloud SDK credentials) to be provided in the form of environment variables or Java system properties, which by definition are accessible by all connectors scheduled on the same Connect worker node.
-
Risk of resource leaks_ _: Incorrectly implemented connectors can cause memory and thread leaks after they were stopped, resulting in out-of-memory errors after stopping and restarting them several times, potentially impacting other connectors and tasks running on the same Connect worker node.
-
Can’t use Kubernetes health checks: as health checks (such as liveness probes) work on the container level, a failed health check would restart the container, and thus Connect worker node with all its connectors, even if only one connector is actually failing. On the other hand, when relying on Connect itself to restart failed connectors and/or tasks, that’s not visible at the level of the Kubernetes control plane, resulting potentially in a false impression of a good health status of a connector, while it actually is in a restarting loop.
-
Can’t easily examine logs of a single connector: When examining the logs of a Kafka Connect pod, messages from multiple running connectors will potentially show up in an interweaved way, depending on the specific logger configurations; as log messages can be prefixed with the connector name, that’s not that much of an issue when analyzing logs in dedicated tools like Logstash or Splunk, but it can be challenging when looking at the raw pod logs on the command line or via a Kubernetes web console.
-
Can’t run multiple versions of one connector: As connectors are solely identified by their classname, it’s not possible to set up a connector instance of a specific version in case there’s multiple versions of that connector present.
Lastly, a third category of issues with running Connect on Kubernetes stems from the inherently mutable design of the system and the ability to dynamically instantiate and reconfigure connectors at runtime via a REST API.
Without proper discipline, this can quickly lead to a lack of insight into the connector configuration applying at a given time (in Strimzi, this is solved by preferrably deploying connectors via custom Kubernetes resources, rather than invoking the REST API directly). In fact, the REST API itself can be a source of issues: access to it needs to be secured in production use cases, also I’ve come across multiple reports over the years (and witnessed myself) where the REST API became unresponsive, while Connect itself still was running. It’s not exactly clear why this happened, but one potential course could be a buggy connector, consuming 100% of CPU cycles, leaving not enough resources for the REST API worker threads. Essentially, I think that such a control plane element like a REST API shouldn’t really be exposed on each member of a data plane, as represented by Connect worker nodes.
Based on all these challenges, in particular those around lacking isolation between different connectors, many users of Kafka Connect stick to the practice of actually not deploying multiple connectors into shared worker clusters, but instead operate a dedicated cluster of Kafka Connect for each connector. This could be a cluster with a node count equal to the configured number of tasks, essentially resulting in 1:1 mapping of tasks to worker processes. Some users also deploy a number of spare workers for fail-over purposes. In fact, that’s the recommendation we’ve been giving to users in the Debezium community for a long time, and it also tends to be a common choice amongst providers of managed Kafka Connect services. Another approach taken by some teams is to deploy specific Connect clusters per connector type , preventing interferences between different kinds of connectors.
All these strategies can help to run connectors for running connectors safely and reliably, but the operational overhead of running multiple Connect clusters is evident.
A Vision for Kubernetes-native Kafka Connect
Having explored the potential issues with running Kafka Connect on Kubernetes, let’s finally discuss how Connect could be reimagined for being more Kubernetes-friendly. What are the parts that could remain? Which things would have to change? Many of the questions and shortcomings raised above — such as workload isolation, applying resource constraints, capability-based scheduling, lifecycle management — have been solved by Kubernetes at the pod level already, so how could that foundation be leveraged for Kafka Connect?
To put a disclaimer first: this part of this post may be a bit dissatisfying to read for some, as it merely describes an idea, I haven’t actually implemented any of this. My line of thinking is to hopefully ignite a discussion in the community and gauge the general level of interest, perhaps even motivating someone in the community to follow through and make this a reality. At least, that’s the plan :)
The general idea is to keep all the actual runtime bits and pieces of Connect: that’s key to being able to run all the amazing existing connectors out there, which are implemented against Connect’s framework interfaces. All the semantics and behaviors, like converters and SMTs, retries, dead-letter queue support, the upcoming exactly-once support for source connectors (KIP-618), all that could just be used as is.
But the entire layer for forming and coordinating clusters of worker nodes and distributing tasks amongst them would be replaced by a Kubernetes operator. To quote the official docs, "operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop". The overall architecture would look like this:
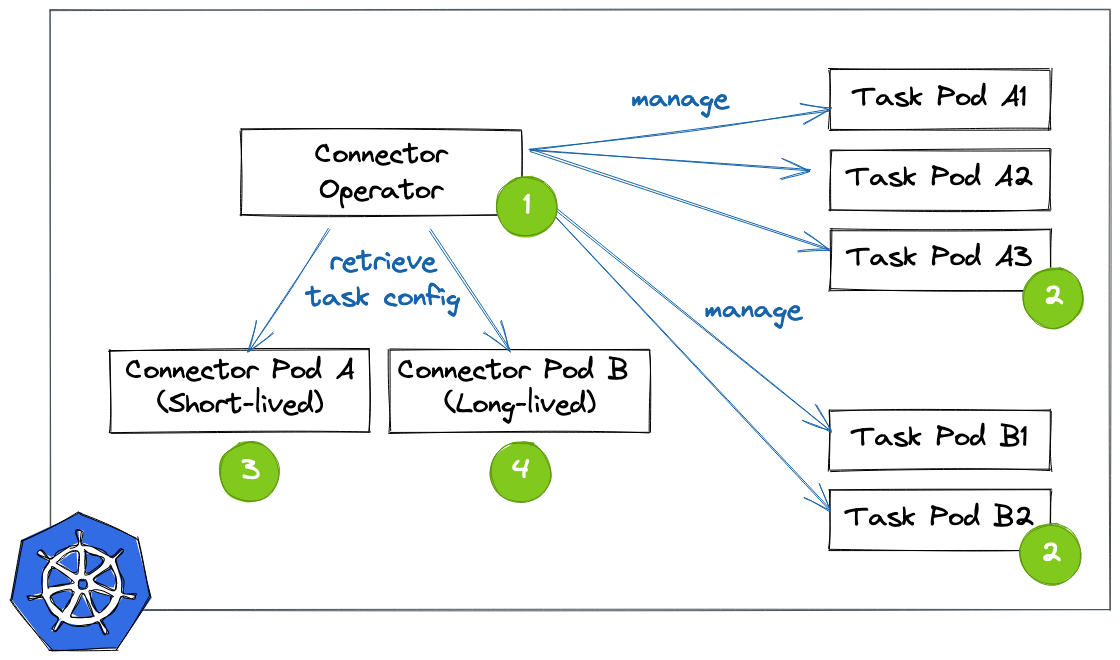
In this envisioned model for Kafka Connect, such an operator would spin up one separate Kubernetes pod (and thus JVM process) for each connector task of a connector. Conceptually, those task processes would be somewhat of a mixture between today’s Connect standalone and distributed modes. Like standalone mode in the sense, that there would be no coordination amongst worker nodes and also no capability to dynamically reconfigure or start and stop a running task; each process/pod would run exactly one task in isolation, coordinated by the operator. Similar to distributed mode in the sense, that there would be a read-only REST API for health information, and that connector offsets would be stored in a Kafka topic, so as to avoid any pod-local state. There wouldn’t be the need for the configuration topic though, as the configuration would be passed upon start-up to the task pods (again akin to standalone mode today, e.g. by mapping a properties file to the pod), with the custom Kubernetes resources defining the connectors being the "system of record" for their configuration.
For this to work, the connector configuration needs to be pre-sliced into task-specific chunks. This could happen in two different ways, depending on the implementation of the specific connectors. For connectors which have a static set of tasks which doesn’t change at runtime (that’s the case for the Debezium connectors, for instance), the operator would deploy a short-lived pod on the Kubernetes cluster which runs the actual Connector implementation class and invoke its taskConfigs(int maxTasks) method . This could be implemented using a Kubernetes job, for instance. Once the operator has received the result (a map with one configuration entry per task), the connector pod can be stopped again and the operator will deploy one pod for each configured task, passing its specific configuration to the pod.
Things get a bit more tricky if connectors dynamically change the number and/or configuration of tasks at runtime, which also is possible with Connect. For instance, that’s the case for the MirrorMaker 2 connector. Such a connector typically spins up a dedicated thread upon start-up which monitors some input resource. If that resource’s state changes (say, a new topic to replicate gets detected by MirrorMaker 2), it invokes the ConnectorContext::requestTaskReconfiguration() method, which in turn lets Connect retrieve the task configuration from the connector. This requires a permanently running pod for that connector class . Right now, there’d be no way for the operator to know whether that connector pod can be short-lived (static task set) or must be long-lived (dynamic task set). Either Connect itself would define some means of metadata for connectors to declare that information, or it could be part of the Kubernetes custom resource for a connector described in the next section.
The configuration of connectors would happen — the Kubernetes way — via custom resources. This could look rather similar to how Connect and connectors are deployed via CRs with Strimzi today; the only difference being that there’d be one CR which describes both Connect (and the resource limits to apply, the connector archive to run) and the actual connector configuration. Here’s an example how that could look like (again, that’s a sketch of how such a CR could look like, this won’t work with Strimzi right now):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: debezium-connect-cluster
spec:
version: 3.2.0
bootstrapServers: debezium-cluster-kafka-bootstrap:9092
config:
config.providers: secrets
config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
connector:
class: io.debezium.connector.mysql.MySqlConnector
tasksMax: 1
database.hostname: mysql
database.port: 3306
database.user: ${secrets:debezium-example/debezium-secret:username}
database.password: ${secrets:debezium-example/debezium-secret:password}
database.server.id: 184054
database.server.name: mysql
database.include.list: inventory
database.history.kafka.bootstrap.servers: debezium-cluster-kafka-bootstrap:9092
database.history.kafka.topic: schema-changes.inventory
build:
output:
type: docker
image: 10.110.154.103/debezium-connect-mysql:latest
plugins:
- name: debezium-mysql-connector
artifacts:
- type: tgz
url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.9.0.Final/debezium-connector-mysql-1.9.0.Final-plugin.tar.gz
The operator would react to the creation, modification, or deletion of this resource, retrieve the (initial) task configuration as described above and spin up corresponding connector and task pods. To stop or restart a connector or task, the user would update the resource state accordingly, upon which the operator would stop and restart the affected pod(s).
Such an operator-based design addresses all the concerns for running Connect on Kubernetes identified above:
-
Only one component in charge of workload distribution: by removing Connect’s own clustering layer from the picture, the scheduling of tasks to compute resources is completely left to one component, the operator; it will determine the number and configuration of tasks to be executed and schedule a pod for each of them; regular health checks can be used for monitoring the state of each task, restarting failed task pods as needed; a degraded health state should be exposed if a connector task is in a retrying loop, so as to make this situation apparent at the Kubernetes level; if a pod crashes, it can be restarted by the operator on the same or another node of the Kubernetes cluster, not requiring any kind of task rebalancing from a Connect perspective. Node selectors could be used to pin a task to specific node groups, e.g. in a specific region or availability zone.
-
One JVM process and Kubernetes pod per task: by launching each task in its own process, all the isolation issues discussed above can be avoided, preventing multiple tasks from negatively impacting each other. If needed, Kubernetes resource limits can be put in place in order to effectively cap the resources available to one particular task, such as CPU and RAM, while also allowing to schedule all the task pods tightly packed onto the compute nodes, making efficient use of the available resources. As each process runs exactly one task, log files are easy to consume and analyze. Scaling out can happen by increasing a single configuration parameter in the CR, and a corresponding number of task pods will be deployed by the operator. Thread leaks become a non-issue too, as there would be no notion of stopping or pausing a task; instead, just the pod itself would be stopped for that purpose, terminating the JVM process running inside of it. On the downside, the overall memory consumption across all the tasks would be increased, as there would be no amortization of Connect classes loaded into JVM processes shared by multiple tasks. Considering the significant advantages of process-based isolation, this seems like an acceptable trade-off, just as Java application developers largely have moved on from the model of co-deploying several applications into shared application server instances.
-
Immutable design: by driving configuration solely through Kubernetes resources and passing the resulting Connect configuration as parameters to the Connect process upon start-up, there’s no need for exposing a mutating REST API (there’d still be a REST endpoint exposing health information), making things more secure and potentially less complex internally, as the entire machinery for pausing/resuming, dynamically reconfiguring and stopping tasks could be removed. At any time, a connector’s configuration would be apparent by examining its CR, which ideally should be sourced from an SCM (GitOps).
Looking further out into the future, such a design for making Kafka Connect Kubernetes-native would also allow for other, potentially very interesting explorations: for instance one could compile connectors into native binaries using GraalVM, resulting in a significantly lower consumption of memory and faster start-up times (e.g. when reconfiguring a connector and subsequently restarting the corresponding pod), making that model very interesting for densely packed Kubernetes environments. A buildtime toolkit like Quarkus could be used for producing specifically tailored executables, which run exactly one single connector task on top of the Connect framework infrastructure, a bit similar to how Camel-K works under the hood. Ultimately, such Kubernetes-native design could even open up the door to Kafka connectors being built in languages and runtimes other than Java and the JVM, similar to the route explored by the Conduit project.
If you think this all sounds exciting and should become a reality, I would love to hear from you. One aspect of specific interest will be which of the proposed changes would have to be implemented within Kafka Connect itself (vs. a separate operator project, for instance under the Strimzi umbrella), without disrupting non-Kubernetes users. In any case, it would be amazing to see the Kafka community at large take its steps towards making Connect truly Kubernetes-native and fully taking advantage of this immensely successful container orchestration platform!
Many thanks to Tom Bentley, Tom Cooper, Ryanne Dolan, Neil Buesing, Mickael Maison, Mattia Mascia, Paolo Patierno, Jakub Scholz, and Kate Stanley for providing their feedback while writing this post!