
Do you remember Angus "Mac" MacGyver? The always creative protagonist of the popular 80ies/90ies TV show, who could solve about any problem with nothing more than a Swiss Army knife, duct tape, shoe strings and a paper clip?
The single message transformations (SMTs) of Kafka Connect are almost as versatile as MacGyver’s Swiss Army knife:
-
How to change the timezone or format of date/time message fields?
-
How to change the topic a specific message gets sent to?
-
How to filter out specific records?
SMTs can be the answer to these and many other questions that come up in the context of Kafka Connect. Applied to source or sink connectors, SMTs allow to modify Kafka records before they are sent to Kafka, or after they are consumed from a topic, respectively.
In this post I’d like to focus on some interesting (hopefully anyways) usages of SMTs. Those use cases are mostly based on my experiences from using Kafka Connect with Debezium, an open-source platform for change data capture (CDC). I also got some great pointers on interesting SMT usages when asking the community about this on Twitter some time ago:
I definitely recommend to check out the thread; thanks a lot to all who replied! In order to learn more about SMTs in general, how to configure them etc., refer to the resources given towards the end of this post.
For each category of use cases, I’ve also asked our sympathetic TV hero for his opinion on the usefulness of SMTs for the task at hand. You can find his rating at the end of each section, ranging from 📎 (poor fit) to 📎📎📎📎📎 (perfect fit).
Format Conversions
Probably the most common application of SMTs is format conversion, i.e. adjustments to type, format and representation of data. This may apply to entire messages, or to specific message attributes. Let’s first look at a few examples for converting individual message attribute formats:
-
Timestamps: Different systems tend to have different assumptions of how timestamps should be typed and formatted. Debezium for instance represents most temporal column types as milli-seconds since epoch. Change event consumers on the other hand might expect such date and time values using Kafka Connect’s
Datetype, or as an ISO-8601 formatted string, potentially using a specific timezone -
Value masking: Sensitive data might have be to masked or truncated, or specific fields should even be removed altogether; the
org.apache.kafka.connect.transforms.MaskFieldandReplaceFieldSMTs shipping with Kafka Connect out of the box come in handy for that -
Numeric types: Similar to timestamps, requirements around the representation of (decimal) numbers may differ between systems; e.g. Kafka Connect’s
Decimaltype allows to convey arbitrary-precision decimals, but its binary representation of numbers might not be supported by all sink connectors and consumers -
Name adjustments: Depending on the chosen serialization formats, specific field names might be unsupported; when working with Apache Avro for instance, field names must not start with a number
In all these cases, either existing, ready-made SMTs or bespoke implementations can be used to apply the required attribute type and/or format conversions.
When using Kafka Connect for integrating legacy services and databases with newly built microservices, such format conversions can play an important role for creating an anti-corruption layer: by using better field names, choosing more suitable data types or by removing unneeded fields, SMTs can help to shield a new service’s model from the oddities and quirks of the legacy world.
But SMTs cannot only modify the representation of single fields, also the format and structure of entire messages can be adjusted.
E.g. Kafka Connect’s ExtractField transformation allows to extract a single field from a message and propagate that one.
A related SMT is Debezium’s SMT for change event flattening.
It can be used to convert the complex Debezium change event structure with old and new row state, metadata and more, into a flat row representation, which can be consumed by many existing sink connectors.
SMTs also allow to fine-tune schema namespaces; that can be of interest when working with a schema registry for managing schemas and their versions, and specific schema namespaces should be enforced for the messages on given topics.
Two more, very useful examples of SMTs in this category are kafka-connect-transform-xml and kafka-connect-json-schema by Jeremy Custenborder, which will take XML or text and produce a typed Kafka Connect Struct,
based on a given XML schema or JSON schema, respectively.
Lastly, as a special kind of format conversion, SMTs can be used to modify or set the key of Kafka records. This may be desirable if a source connector doesn’t produce any meaningful key, but one can be extracted from the record value. Also changing the message key can be useful, when considering subsequent stream processing. Choosing matching keys right at the source side e.g. allows for joining multiple topics via Kafka Streams, without the need for re-keying records.
Mac’s rating: 📎📎📎📎📎 SMTs are the perfect tool for format conversions of Kafka Connect records
Ensuring Backwards Compatibility
Changes to the schema of Kafka records can potentially be disruptive for consumers. If for instance a record field gets renamed, a consumer must be adapted accordingly, reading the value using the new field name. In case a field gets dropped altogether, consumers must not expect this field any longer.
Message transformations can help with such transition from one schema version to the next, thus reducing the coupling of the lifecycles of message producers and consumers. In case of a renamed field, an SMT could add the field another time, using the original name. That’ll allow consumers to continue reading the field using the old name and to be upgraded to use the new name at their own pace. After some time, once all consumers have been adjusted, the SMT can be removed again, only exposing the new field name going forward. Similarly, a field that got removed from a message schema could be re-added, e.g. using some sort of constant placeholder value. In other cases it might be possible to derive the field value from other, still existing fields. Again consumers could then be updated at their own pace to not expect and access that field any longer.
It should be said though that there are limits for this usage: e.g. when changing the type of a field, things quickly become tricky. One option could be a multi-step approach where at first a separate field with the new type is added, before renaming it again as described above.
Mac’s rating: 📎📎📎 SMTs can primarily help to address basic compatibility concerns around schema evolution
Filtering and Routing
When applied on the source side, SMTs allow to filter out specific records produced by the connector. They also can be used for controlling the Kafka topic a record gets sent to. That’s in particular interesting when filtering and routing is based on the actual record contents. In an IoT scenario for instance where Kafka Connect is used to ingest data from some kind of sensors, an SMT might be used to filter out all sensor measurements below a certain threshold, or route measurement events above a threshold to a special topic.
Debezium provides a range of SMTs for record filtering and routing:
-
The logical topic routing SMT allows to send change events originating from multiple tables to the same Kafka topic, which can be useful when working with partition tables in Postgres, or with data that is sharded into multiple tables
-
The
FilterandContentBasedRouterSMTs let you use script expressions in languages such as Groovy or JavaScript for filtering and routing change events based on their contents; such script-based approach can be an interesting middleground between ease-of-use (no Java code must be compiled and deployed to Kafka Connect) and expressiveness; e.g. here is how the routing SMT could be used with GraalVM’s JavaScript engine for routing change events from a table with purchase orders to different topics in Kafka, based on the order type:1 2 3 4 5 6 7 8
... transforms=route transforms.route.type=io.debezium.transforms.ContentBasedRouter transforms.route.topic.regex=.*purchaseorders transforms.route.language=jsr223.graal.js transforms.route.topic.expression= value.after.ordertype == 'B2B' ? 'b2b_orders' : 'b2c_orders' ... -
The outbox event router comes in handy when implementing the transactional outbox pattern for data propagation between microservices: it can be used to send events originating from a single outbox table to a specific Kafka topic per aggregate (when thinking of domain driven design) or event type
There are also two SMTs for routing purposes in Kafka Connect itself: RegexRouter which allows to re-route records two different topics based on regular expressions, and TimestampRouter for determining topic names based on the record’s timestamp.
While routing SMTs usually are applied to source connectors (defining the Kafka topic a record gets sent to), it can also make sense to use them with sink connectors. That’s the case when a sink connector derives the name of downstream table names, index names or similar from the topic name.
Mac’s rating: 📎📎📎📎📎 Message filtering and topic routing — no problem for SMTs
Tombstone Handling
Tombstone records are Kafka records with a null value.
They carry special semantics when working with compacted topics:
during log compaction, all records with the same key as a tombstone record will be removed from the topic.
Tombstones will be retained on a topic for a configurable time before compaction happens (controlled via delete.retention.ms topic setting),
which means that also Kafka Connect sink connectors need to handle them.
Unfortunately though, not all connectors are prepared for records with a null value,
typically resulting in NullPointerExceptions and similar.
A filtering SMT such as the one above can be used to drop tombstone records in such case.
But also the exact opposite — producing tombstone records — can be useful:
some sink connectors use tombstone records as the indicator to delete corresponding rows from a downstream datastore.
Now when using a CDC connector like Debezium to capture changes from a database where "soft deletes" are used (i.e. records are not physically deleted, but a logically deleted flag is set to true when deleting a record), those change events will be exported as update events (which they technically are).
A bespoke SMT can be used to translate these update events into tombstone records, triggering the deletion of corresponding records in downstream datastores.
Mac’s rating: 📎📎📎📎 SMTs work well to discard tombstones or convert soft delete events into tombstones. What’s not possible though is to keep the original event and produce an additional tombstone record at the same time
Externalizing Large Payloads
Even some advanced enterprise application patterns can be implemented with the help of SMTs, one example being the claim check pattern. This pattern comes in handy in situations like this:
A message may contain a set of data items that may be needed later in the message flow, but that are not necessary for all intermediate processing steps. We may not want to carry all this information through each processing step because it may cause performance degradation and makes debugging harder because we carry so much extra data.
— Gregor Hohpe, Bobby Woolf; Enterprise Application Patterns
A specific example could again be a CDC connector that captures changes from a database table Users, with a BLOB column that contains the user’s profile picture
(surely not a best practice, still not that uncommon in reality…).
|
Apache Kafka and Large Messages
Apache Kafka isn’t meant for large messages. The maximum message size is 1 MB by default, and while this can be increased, benchmarks are showing best throughput for much smaller messages. Strategies like chunking and externalizing large payloads can thus be vital in order to ensure a satisfying performance. |
When propagating change data events from that table to Apache Kafka, adding the picture data to each event poses a significant overhead. In particular, if the picture BLOB hasn’t changed between two events at all.
Using an SMT, the BLOB data could be externalized to some other storage. On the source side, the SMT could extract the image data from the original record and e.g. write it to a network file system or an Amazon S3 bucket. The corresponding field in the record would be updated so it just contains the unique address of the externalised payload, such as the S3 bucket name and file path:
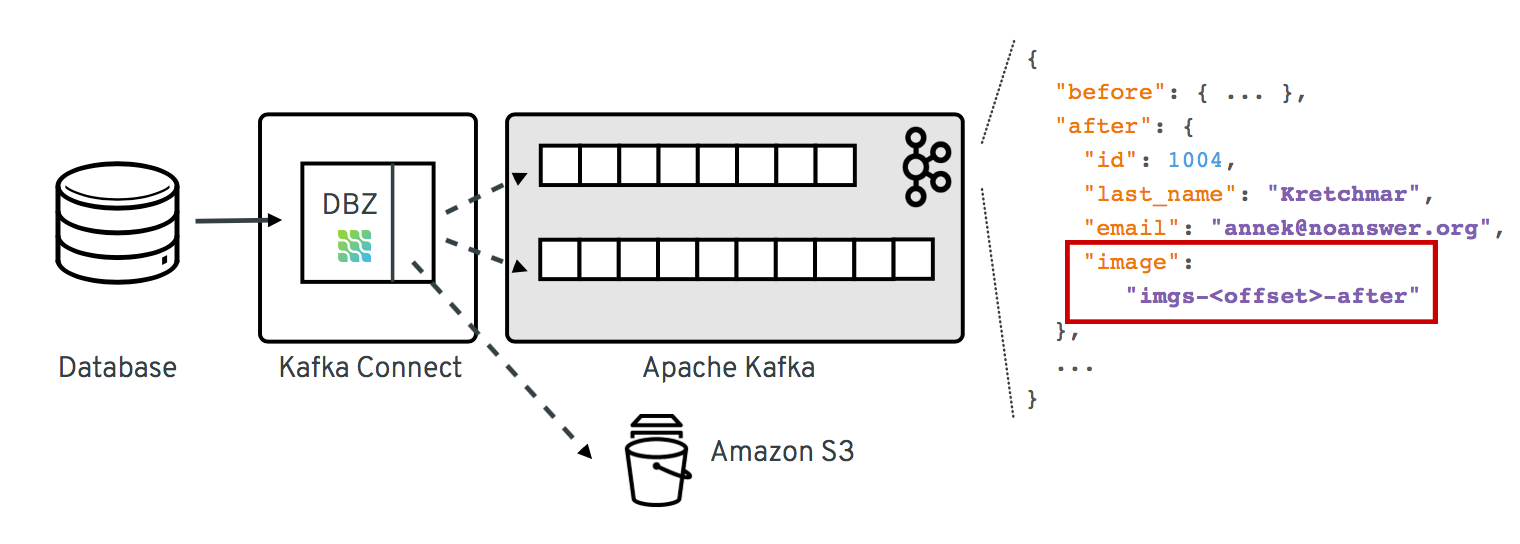
As an optimization, it could be avoided to re-upload unchanged file contents another time by comparing earlier and current hash of the externalized file.
A corresponding SMT instance applied to sink connectors would retrieve the identifier of the externalized files from the incoming record, obtain the contents from the external storage and put it back into the record before passing it on to the connector.
Mac’s rating: 📎📎📎📎 SMTs can help to externalize payloads, avoiding large Kafka records. Relying on another service increases overall complexity, though
Limitations
As we’ve seen, single message transformations can help to address quite a few requirements that commonly come up for users of Kafka Connect. But there are limitations, too; Like MacGyver, who sometimes has to reach for some other tool than his beloved Swiss Army knife, you shouldn’t think of SMTs as the perfect solution all the time.
The biggest shortcoming is already hinted at in their name: SMTs only can be used to process single records, one at a time. E.g. you cannot split up a record into multiple ones using an SMT, as they only can return (at most) one record. Also any kind of stateful processing, like aggregating data from multiple records, or correlating records from several topics is off limits for SMTs. For such use cases, you should be looking at stream processing technologies like Kafka Streams and Apache Flink; also integration technologies like Apache Camel can be of great use here.
One thing to be aware of when working with SMTs is configuration complexity; when using generic, highly configurable SMTs, you might end up with lengthy configuration that’s hard to grasp and debug. You might be better off implementing a bespoke SMT which is focussing on one particular task, leveraging the full capabilities of the Java programming language.
|
SMT Testing
Whether you use ready-made SMTs by means of configuration, or you implement custom SMTs in Java, testing your work is essential. While unit tests are a viable option for basic testing of bespoke SMT implementations, integration tests running against Kafka Connect connectors are recommended for testing SMT configurations. That way you’ll be sure that the SMT can process actual messages and it has been configured the way you intended to. Testcontainers and the Debezium support for Testcontainers are a great foundation for setting up all the required components such as Apache Kafka, Kafka Connect, connectors and the SMTs to test. |
A specific feature I wished for every now and then is the ability to apply SMTs only to a specific sub-set of the topics created or consumed by a connector. In particular if connectors create different kinds of topics (like an actual data topic and another one with with metadata), it can be desirable to apply SMTs only to the topics of one group but not the other. This requirement is captured in KIP-585 ("Filter and Conditional SMTs"), please join the discussion on that one if you got requirements or feedback related to that.
Learning More
There are several great presentations and blog posts out there which describe in depth what SMTs are, how you can implement your own one, how they are configured etc.
Here are a few resources I found particularly helpful:
-
KIP-66: The original KIP (Kafka Improvement Proposal) that introduced SMTs
-
Singe Message Transforms are not the Transformations You’re Looking For: A great overview on SMTs, their capabilities as well as limitations, by Ewen Cheslack-Postava
-
A hands-on experience with Kafka Connect SMTs: In-depth blog post on SMT use cases, things to be aware of and more, by Gian D’Uia
Now, considering this wide range of use cases for SMTs, would MacGyver like and use them for implementing various tasks around Kafka Connect? I would certainly think so. But as always, the right tool for the job must be chosen: sometimes an SMT may be a great fit, another time a more flexible (and complex) stream processing solution might be preferable.
Just as MacGyver, you got to make a call when to use your Swiss Army knife, duct tape or a paper clip.
Many thanks to Hans-Peter Grahsl for his feedback while writing this blog post!