
Having a search functionality for my blog has been on my mind for quite some time; I’d like to give users the opportunity to find specific contents on this blog right here on this site, without having to use an external search engine. That’s not only nice in terms of user experience, but also having insight into the kind of information readers look for on this blog should help me to identify interesting things to write about in the future.
Now this blog is a static site — generated using Hugo, hosted on GitHub Pages — which makes this an interesting challenge. I didn’t want to rely on an external search service (see "Why No External Search Service" below for the reasoning), and also a purely client-side solution as described in this excellent blog post didn’t seem ideal. While technically fascinating, I didn’t like the fact that it requires shipping the entire search index to the client for executing search queries. Also things like result highlighting, customized result scoring, word stemming, fuzzy search and more seemed a bit more than I’d be willing to implement on the client.
All these issues have largely been solved on the server-side by libraries such as Apache Lucene for quite some time. Using a library like Lucene means implementing a custom server-side process, though. How to deploy such service? Operating a VM 24/7 with my search backend for what’s likely going to be not more than a few dozen queries per month seemed a bit like overkill.
So after some consideration I decided to implement my own search functionality, based on the highly popular Apache Lucene library, deployed as a Serverless application, which is started on-demand if a user runs a query on my website. In the remainder of this post I’m going to describe the solution I came up with and how it works.
If you like, you can try it out right now, this post is about this little search input control at the top right of this page!
|
Why No External Search Service?
When tweeting about my serverless search experiment, one of the questions was "What’s wrong with Algolia?". To be very clear, there’s nothing wrong with it at all. External search services like Algolia, Google Custom Search, or an Elasticsearch provider such as Bonsai promise an easy-to-use, turn-key search functionality which can be a great choice for your specific use case. However, I felt that none of these options would provide me the degree of control and customizability I was after. I also ruled out any "free" options, as they’d either mean having ads or paying for the service with the data of myself or that of my readers. And to be honest, I also just fancied the prospect of solving the problem by myself, instead of relying on an off-the-shelf solution. |
Why Serverless?
First of all, let’s discuss why I opted for a Serverless solution. It boils down to three reasons:
-
Security: While it’d only cost a few EUR per month to set up a VM with a cloud provider like Digital Ocean or Hetzner, having to manage a full operating system installation would require too much of my attention; I don’t want someone to mine bitcoins or doing other nasty things on a box I run, just because I failed to apply some security patch
-
Cost: Serverless does not only promise to scale-out (and let’s be honest, there likely won’t be millions of search queries on my blog every month), but also scale-to-zero. As Serverless is pay-per-use and there are free tiers in place e.g. for AWS Lambda, this service ideally should cost me just a few cents per month
-
Learning Opportunity: Last but not least, this also should be a nice occasion for me to dive into the world of Serverless, by means of designing, developing and running a solution for a real-world problem, exploring how Java as my preferred programming language can be used for this task
Solution Overview
The overall idea is quite simple: there’s a simple HTTP service which takes a query string, runs the query against a Lucene index with my blog’s contents and returns the search results to the caller. This service gets invoked via JavaScript from my static blog pages, where results are shown to the user.
The Lucene search index is read-only and gets rebuilt whenever I update the blog. It’s baked into the search service deployment package, which that way becomes fully immutable. This reduces complexities and the attack surface at runtime. Surely that’s not an approach that’s viable for more dynamic use cases, but for a blog that’s updated every few weeks, it’s perfect. Here’s a visualization of the overall flow:
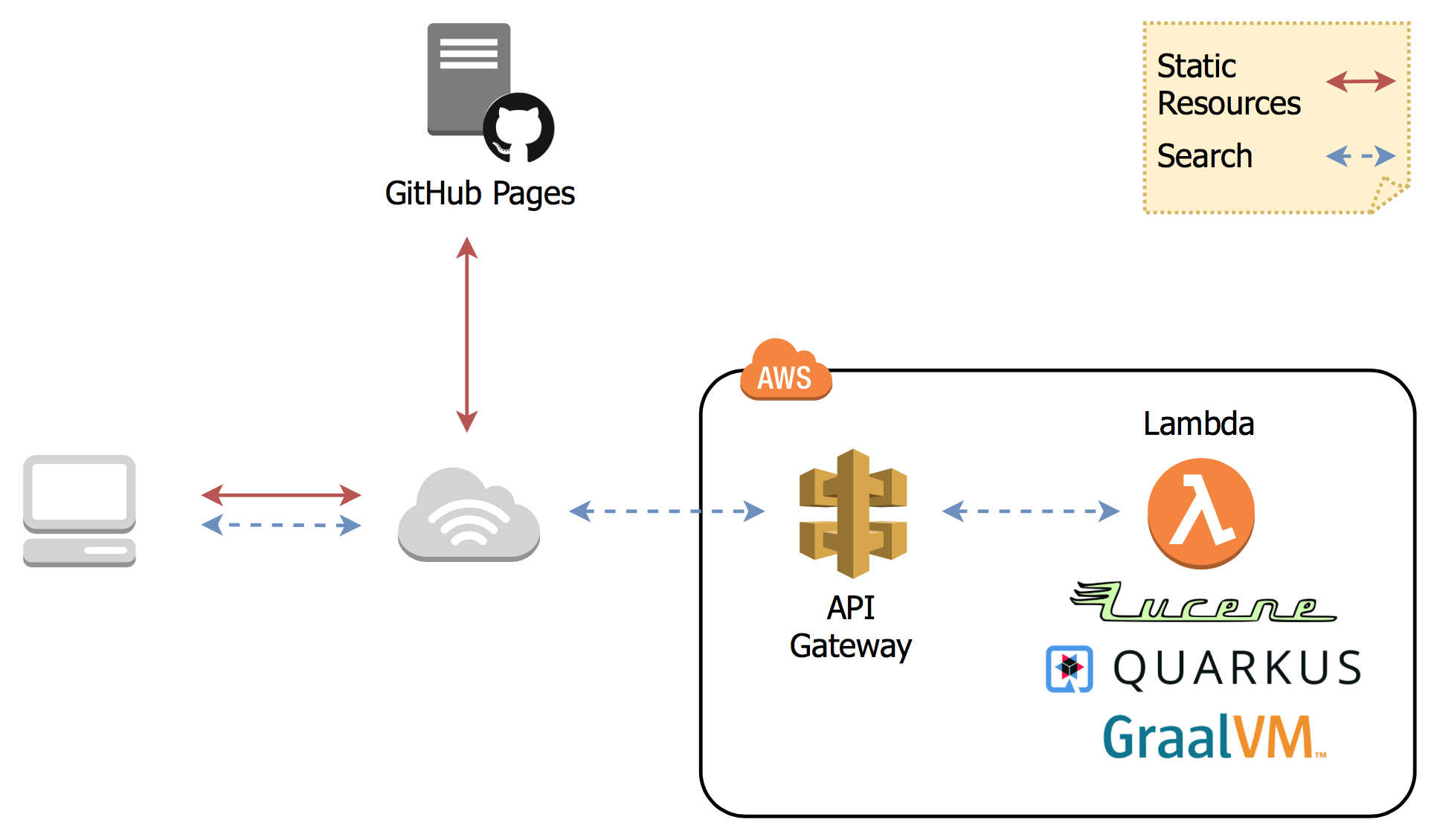
The search service is deployed as a Serverless function on AWS Lambda. One important design goal for me is to avoid lock-in to any specific cloud provider: the solution should be portable and also be usable with container-based Serverless approaches like Knative.
Relying on a Serverless architecture means its start-up time must be a matter of milli-seconds rather than seconds, so to not have a user wait for a noticeable amount of time in case of a cold start. While substantial improvements have been made in recent Java versions to improve start-up times, it’s still not ideal for this kind of use case. Therefore, the application is compiled into a native binary via Quarkus and GraalVM, which results in a start-up time of ~30 ms on my laptop, and ~180 ms when deployed to AWS Lambda. With that we’re in a range where a cold start won’t impact the user experience in any significant way.
The Lambda function is exposed to callers via the AWS API Gateway, which takes incoming HTTP requests, maps them to calls of the function and converts its response into an HTTP response which is sent back to the caller.
Now let’s dive down a bit more into the specific parts of the solution. Overall, there are four steps involved:
-
Data extraction: The blog contents to be indexed must be extracted and converted into an easy-to-process data format
-
Search backend implementation: A small HTTP service is needed which exposes the search functionality of Apache Lucene, which in particular requires some steps to enable Lucene being used in a native GraalVM binary
-
Integration with the website: The search service must be integrated into the static site on GitHub Pages
-
Deployment: Finally, the search service needs to be deployed to AWS API Gateway and Lambda
Data Extraction
The first step was to obtain the contents of my blog in an easily processable format. Instead of requiring something like a real search engine’s crawler, I essentially only needed to have a single file in a structured format which then can be passed on to the Lucene indexer.
This task proved rather easy with Hugo; by means of a custom output format it’s straight-forward to produce a JSON file which contains the text of all my blog pages. In my config.toml I declared the new output format and activate it for the homepage (largely inspired by this write-up):
1
2
3
4
5
6
7
8
[outputFormats.SearchIndex]
mediaType = "application/json"
baseName = "searchindex"
isPlainText = true
notAlternative = true
[outputs]
home = ["HTML","RSS", "SearchIndex"]
The template in layouts/_default/list.searchindex.json isn’t too complex either:
1
2
3
4
5
{{- $.Scratch.Add "searchindex" slice -}}
{{- range $index, $element := .Site.Pages -}}
{{- $.Scratch.Add "searchindex" (dict "id" $index "title" $element.Title "uri" $element.Permalink "tags" $element.Params.tags "section" $element.Section "content" $element.Plain "summary" $element.Summary "publicationdate" ($element.Date.Format "Jan 2, 2006")) -}}
{{- end -}}
{{- $.Scratch.Get "searchindex" | jsonify -}}
The result is this JSON file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[
...
{
"content": "The JDK Flight Recorder (JFR) is an invaluable tool...",
"id": 12,
"publicationdate": "Jan 29, 2020",
"section": "blog",
"summary": "\u003cdiv class=\"paragraph\"\u003e\n\u003cp\u003eThe \u003ca href=\"https://openjdk.java.net/jeps/328\"\u003eJDK Flight Recorder\u003c/a\u003e (JFR) is an invaluable tool...",
"tags": [
"java",
"monitoring",
"microprofile",
"jakartaee",
"quarkus"
],
"title": "Monitoring REST APIs with Custom JDK Flight Recorder Events",
"uri": "https://www.morling.dev/blog/rest-api-monitoring-with-custom-jdk-flight-recorder-events/"
},
...
]
This file gets automatically updated whenever I republish the blog.
Search Backend Implementation
My stack of choice for this kind of application is Quarkus. As a contributor, I am of course biased, but Quarkus is ideal for the task at hand: built and optimized from the ground up for implementing fast-starting and memory-efficient cloud-native and Serverless applications, it makes building HTTP services, e.g. based on JAX-RS, running on GraalVM a trivial effort.
Now typically a Java library such as Lucene will not run in a GraalVM native binary out-of-the-box. Things like reflection or JNI usage require specific configuration, while other Java features like method handles are only supported partly or not at all.
Apache Lucene in a GraalVM Native Binary
Quarkus enables a wide range of popular Java libraries to be used with GraalVM, but at this point there’s no extension yet which would take care of Lucene. So I set out to implement a small Quarkus extension for Lucene. Depending on the implementation details of the library in question, this can be a more or less complex and time-consuming endeavor. The workflow is like so:
-
compile down an application using the library into a native image
-
run into some sort of exception, e.g. due to types accessed via Java reflection (which causes the GraalVM compiler to miss them during call flow analysis so that they are missing from the generated binary image)
-
fix the issue e.g. by registering the types in question for reflection
-
rinse and repeat
The good thing there is that the list of Quarkus extensions is constantly growing, so that you hopefully don’t have to go through this by yourself. Or if you do, consider publishing your extension via the Quarkus platform, saving others from the same work.
For my particular usage of Lucene, I ran luckily into two issues only.
The first is the usage of method handles in the AttributeFactory class for dynamically instantiating sub-classes of the AttributeImpl type,
which isn’t supported in that form by GraalVM.
One way for dealing with this is to define substitutions,
custom methods or classes which will override a specific original implementation.
As an example, here’s one of the substitution classes I had to create:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@TargetClass(className = "org.apache.lucene.util.AttributeFactory$DefaultAttributeFactory")
public final class DefaultAttributeFactorySubstitution {
public DefaultAttributeFactorySubstitution() {}
@Substitute
public AttributeImpl createAttributeInstance(Class<? extends Attribute> attClass) {
if (attClass == BoostAttribute.class) {
return new BoostAttributeImpl();
}
else if (attClass == CharTermAttribute.class) {
return new CharTermAttributeImpl();
}
else if (...) {
...
}
throw new UnsupportedOperationException("Unknown attribute class: " + attClass);
}
}
During native image creation, the GraalVM compiler will discover all substitute classes and apply their code instead of the original ones.
The other problem I ran into was the usage of method handles in the MMapDirectory class,
which will be used by Lucene by default on Linux when obtaining a file-system backed index directory.
I didn’t explore how to circumvent that, instead I opted for using the SimpleFSDirectory implementation which proved to work fine in my native GraalVM binary.
While this was enough in order to get Lucene going in a native image, you might run into different issues when using other libraries with GraalVM native binaries. Quarkus comes with a rich set of so-called build items which extension authors can use in order to enable external dependencies on GraalVM, e.g. for registering classes for reflective access or JNI, adding additional resources to the image, and much more. I recommend you take a look at the extension author guide in order to learn more.
Besides enabling Lucene on GraalVM, that Quarkus extension also does two more things:
-
Parse the previously extracted JSON file, build a Lucene index from that and store that index in the file system; that’s fairly standard Lucene procedure without anything noteworthy; I only had to make sure that the index fields are stored in their original form in the search index, so that they can be accessed at runtime when displaying fragments with the query hits
-
Register a CDI bean, which allows to obtain the index at runtime via
@Injectdependency injection from within the HTTP endpoint class
A downside of creating binaries via GraalVM is the increased build time: creating a native binary for macOS via a locally installed GraalVM SDK takes about two minutes on my laptop. For creating a Linux binary to be used with AWS Lambda, I need to run the build in a Linux container, which takes about five minutes. But typically this task is only done once when actually deploying the application, whereas locally I’d work either with the Quarkus Dev Mode (which does a live reload of the application as its code changes) or test on the JVM. In any case it’s a price worth paying: only with start-up times in the range of milli-seconds on-demand Serverless cold starts with the user waiting for a response become an option.
The Search HTTP Service
The actual HTTP service implementation for running queries is rather unspectacular; It’s based on JAX-RS and exposes as simple endpoint which can be invoked with a given query like so:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
http "https://my-search-service/search?q=java"
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 4930
Content-Type: application/json
Date: Tue, 21 Jul 2020 17:05:00 GMT
{
"message": "ok",
"results": [
{
"fragment": "...plug-ins. In this post I’m going to explore how the <b>Java</b> Platform Module System's notion of module layers can be leveraged for implementing plug-in architectures on the JVM. We’ll also discuss how Layrry, a launcher and runtime for layered <b>Java</b> applications, can help with this task. A key requirement...",
"publicationdate": "Apr 21, 2020",
"title": "Plug-in Architectures With Layrry and the <b>Java</b> Module System",
"uri": "https://www.morling.dev/blog/plugin-architectures-with-layrry-and-the-java-module-system/"
},
{
"fragment": "...the current behavior indeed is not intended (see JDK-8236597) and in a future <b>Java</b> version the shorter version of the code shown above should work. Wrap-Up In this blog post we’ve explored how invariants on <b>Java</b> 14 record types can be enforced using the Bean Validation API. With just a bit...",
"publicationdate": "Jan 20, 2020",
"title": "Enforcing <b>Java</b> Record Invariants With Bean Validation",
"uri": "https://www.morling.dev/blog/enforcing-java-record-invariants-with-bean-validation/"
},
...
]
}
Internally it’s using Lucene’s MultiFieldQueryParser for parsing the query and running it against the "title" and "content" fields of the index.
It is set to combine multiple terms using the logical AND operator by default (who ever would want the default of OR?), it supports phrase queries given in quotes, and a number of other query operators.
Query hits are highlighted using the FastVectorHighlighter highlighter and SimpleHTMLFormatter as a fallback
(not all kinds of queries can be processed by FastVectorHighlighter).
The highlighter wraps the matched search terms in the returned fragment in <b> tags,
which are styled appropriately in my website’s CSS.
I was prepared to do some adjustments to result scoring, but this wasn’t necessary so far.
Title matches are implicitly ranked higher than content matches due to the shorter length of the title field values.
Implementing the service using a standard HTTP interface instead of relying on specific AWS Lambda contracts is great in terms of local testing as well as portability: I can work on the service using the Quarkus Dev Mode and invoke it locally, without having to deploy it into some kind of Lambda test environment. It also means that should the need arise, I can take this service and run it elsewhere, without requiring any code changes. As I’ll discuss in a bit, Quarkus takes care of making this HTTP service runnable within the Lambda environment by means of a single dependency configuration.
Wiring Things Up
Now it was time to hook up the search service into my blog. I wouldn’t want to have the user navigate to the URL of the AWS API Gateway in their browser; this means that the form with the search text input field cannot actually be submitted. Instead, the default form handling must be disabled, and the search string be sent via JavaScript to the API Gateway URL.
This means the search feature won’t work for users who have JavaScript disabled in their browser. I deemed this an acceptable limitation; in order to avoid unnecessary confusion and frustration, the search text input field is hidden in that case via CSS:
1
2
3
4
5
<noscript>
<style type="text/css">
.search-input { display:none; }
</style>
</noscript>
The implementation of the backend call is fairly standard JavaScript business using the XMLHttpRequest API, so I’ll spare you the details here. You can find the complete implementation in my GitHub repo.
There’s one interesting detail to share though in terms of improving the user experience after a cold start. As mentioned above, the Quarkus application itself starts up on Lambda in about ~180 ms. Together with the initialization of the Lambda execution environment I typically see ~370 ms for a cold start. Add to that the network round-trip times, and a user will feel a slight delay. Nothing dramatical, but it doesn’t have that snappy instant feeling you get when executing the search with a warm environment.
Thinking about the typical user interaction though, the situation can be nicely improved: if a visitor puts the focus onto the search text input field, it’s highly likely that they will submit a query shortly thereafter. We can take advantage of that and have the website send a small "ping" request right at the point when the input field obtains the focus. This gives us enough headstart to have the Lambda function being started before the actual query comes in. Here’s the request flow of a typical interaction (the "Other" requests are CORS preflight requests):
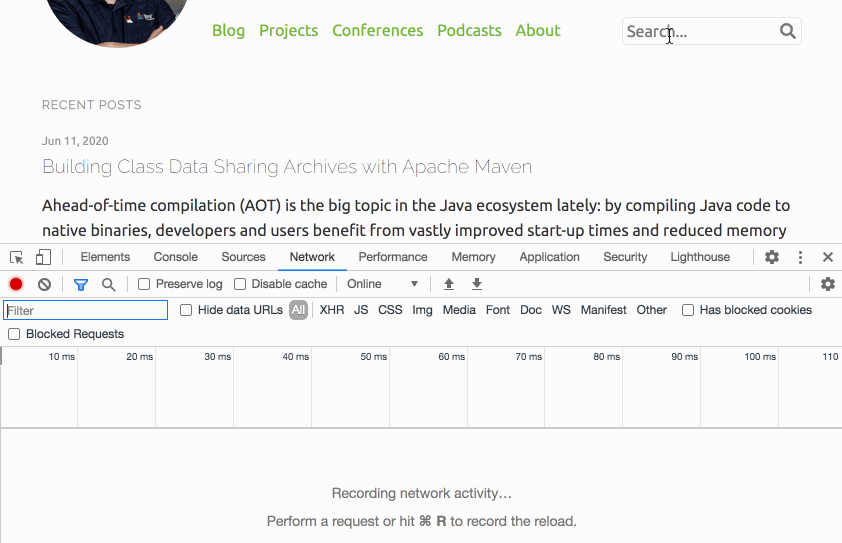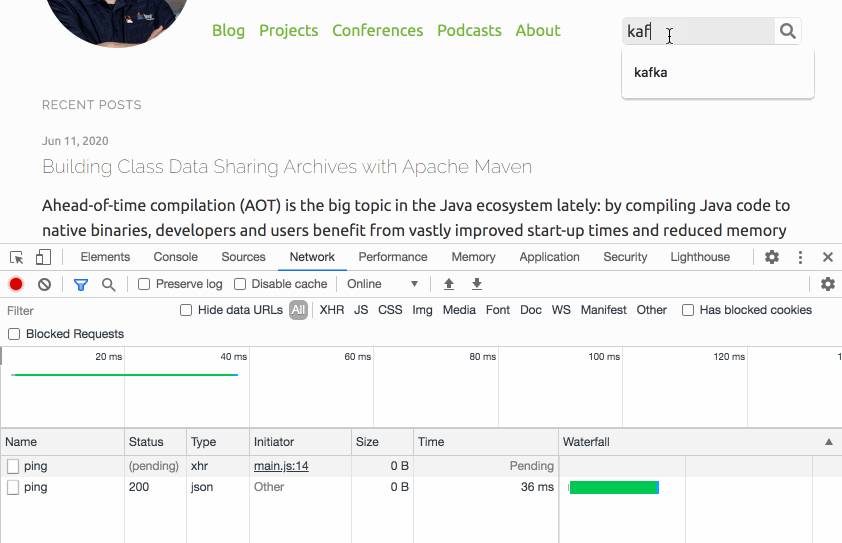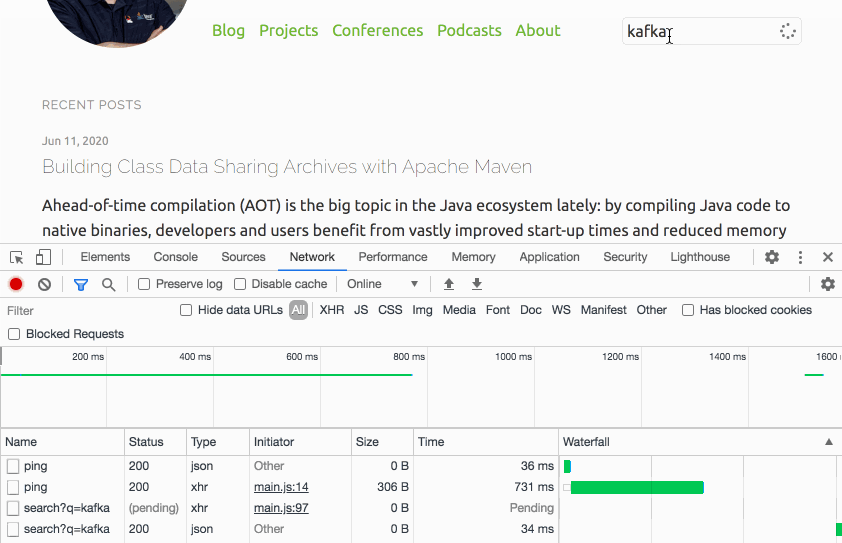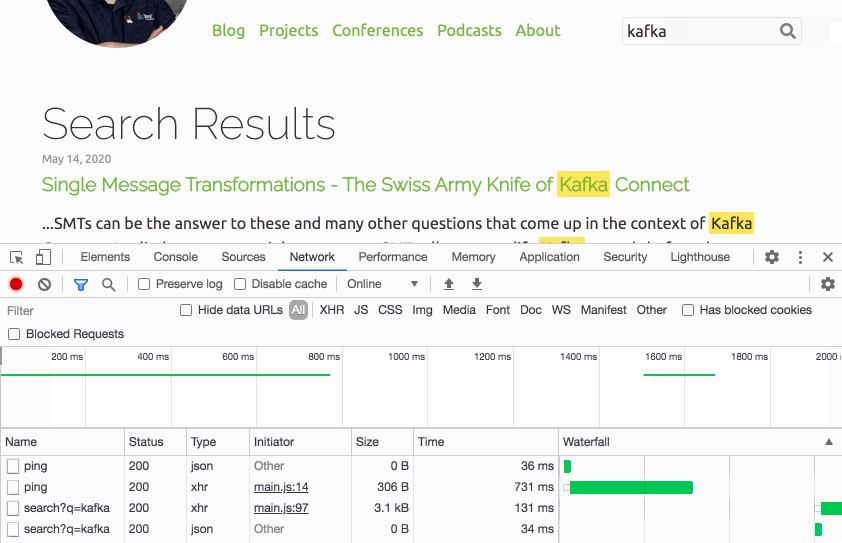
Note how the search call is issued only a few hundred ms after the ping. Now you could beat this e.g. when navigating to the text field using your keyboard and if you were typing really fast. But most users will use their mouse or touchpad to put the cursor into the input, and then change to the keyboard to enter the query, which is time enough for this little trick to work.
The analysis of the logs confirms that essentially all executed queries hit a warmed up Lambda function, making cold starts a non-issue. To avoid any unneeded warm-up calls, they are only done when entering the input field for the first time after loading the page, or when staying on the page for long enough, so that the Lambda might have shut down again due to lack of activity.
Of course you’ll be charged for the additional ping requests, but for the volume I expect, this makes no relevant difference whatsoever.
Deployment to AWS Lambda
The last part of my journey towards a Serverless search function was deployment to AWS Lambda. I was exploring Heroku and Google Cloud Run as alternatives, too. Both allow you to deploy regular container images, which then are automatically scaled on demand. This results in great portability, as things hardly can get any more standard than plain Linux containers.
With Heroku, cold start times proved problematic, though: I observed 5 - 6 seconds, which completely ruling it out. This wasn’t a problem with Cloud Run, and it’d surely work very well overall. In the end I went for AWS Lambda, as its entire package of service runtime, API Gateway and web application firewall seemed more complete and mature to me.
With AWS Lambda, I observed cold start times of less than 0.4 sec for my actual Lambda function, plus the actual request round trip. Together with the warm-up trick described above, this means that a user practically never will get a cold start when executing the search.
You shouldn’t under-estimate the time needed though to get familiar with Lambda itself, the API Gateway which is needed for routing HTTP requests to your function and the interplay of the two.
To get started, I configured some playground Lambda and API in the web console, but eventually I needed something along the lines of infrastructure-as-code, means of reproducible and automated steps for configuring and setting up all the required components. My usual go-to solution in this area is Terraform, but here I settled for the AWS Serverless Application Model (SAM), which is tailored specifically to setting up Serverless apps via Lambda and API Gateway and thus promised to be a bit easier to use.
Building Quarkus Applications for AWS Lambda
Quarkus supports multiple approaches for building Lambda-based applications:
-
You can directly implement Lambda’s APIs like
RequestHandler, which I wanted to avoid though for the sake of portability between different environments and cloud providers -
You can use the Quarkus Funqy API for building portable functions which e.g. can be deployed to AWS, Azure Functions and Google Cloud Functions; the API is really straight-forward and it’s a very attractive option, but right now there’s no way to use Funqy for implementing an HTTP GET API with request parameters, which ruled out this option for my purposes
-
You can implement your Lambda function using the existing and well-known HTTP APIs of Vert.x, RESTEasy (JAX-RS) and Undertow; in this case Quarkus will take care of mapping the incoming function call to the matching HTTP endpoint of the application
Used together with the proxy feature of the AWS API Gateway, the third option is exactly what I was looking for.
I can implement the search endpoint using the JAX-RS API I’m familiar with, and the API Gateway proxy integration together with Quarkus' glue code will take care of everything else for running this.
This is also great in terms of portability:
I only need to add the io.quarkus:quarkus-amazon-lambda-http dependency to my project,
and the Quarkus build will emit a function.zip file which can be deployed to AWS Lambda.
I’ve put this into a separate Maven build profile,
so I can easily switch between creating the Lambda function deployment package and a regular container image with my REST endpoint which I can deploy to Knative and environments like OpenShift Serverless,
without requiring any code changes whatsoever.
The Quarkus Lambda extension also produces templates for the AWS SAM tool for deploying my stack.
They are a good starting point which just needs a little bit of massaging;
For the purposes of cost control (see further below), I added an API usage plan and API key.
I also enabled CORS so that the API can be called from my static website.
This made it necessary to disable the configuration of binary media types which the generated template contains by default.
Lastly, I used a specific pre-configured execution role instead of the default AWSLambdaBasicExecutionRole.
With the SAM descriptor in place, re-building and publishing the search service becomes a procedure of three steps:
1
2
3
4
5
6
7
8
9
10
mvn clean package -Pnative,lambda -DskipTests=true \
-Dquarkus.native.container-build=true
sam package --template-file sam.native.yaml \
--output-template-file packaged.yaml \
--s3-bucket <my S3 bucket>
sam deploy --template-file packaged.yaml \
--capabilities CAPABILITY_IAM \
--stack-name <my stack name>
The lambda profile takes care of adding the Quarkus Lambda HTTP extension,
while the native profile makes sure that a native binary is built instead of a JAR to be run on the JVM.
As I need to build a Linux binary for the Lambda function while running on macOS locally,
I’m using the -Dquarkus.native.container-build=true option,
which will make the Quarkus build running in a container itself,
producing a Linux binary no matter which platform this build itself is executed on.
The function.zip file produced by the Quarkus build has a size of ~15 MB, i.e. it’s uploaded and deployed to Lambda in a few seconds. Currently it also contains the Lucene search index, meaning I need to run the time-consuming GraalVM build whenever I want to update the index. As an optimization I might at some point extract the index into a separate Lambda layer, which then could be deployed by itself, if there were no code changes to the search service otherwise.
Identity and Access Management
A big pain point for me was identity and access management (IAM) for the AWS API Gateway and Lambda. While the AWS IAM is really powerful and flexible, there’s unfortunately no documentation, which would describe the minimum set of required permissions in order to deploy a stack like my search using SAM.
Things work nicely if you use a highly-privileged account, but I’m a strong believer into running things with only the least privileges needed for the job. For instance I don’t want my Lambda deployer to set up the execution role, but rather have it using one I pre-defined. The same goes for other resources like the S3 bucket used for uploading the deployment package.
Identifying the set of privileges actually needed is a rather soul-crushing experience of trial and error (please let me know in the comments below if there’s a better way to do this), which gets complicated by the fact that different resources in the AWS stack expose insufficient privileges in inconsistent ways, or sometimes in no really meaningful way at all when configured via SAM. I spent hours identifying a lacking S3 privilege when trying to deploy a Lambda layer from the Serverless Application Repository.
Hoping to spare others from this tedious work, here’s the policy for my deployment role I came up with:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<deployment-bucket>",
"arn:aws:s3:::<deployment-bucket>/*"
]
},
{
"Effect": "Allow",
"Action": [
"lambda:CreateFunction",
"lambda:GetFunction",
"lambda:GetFunctionConfiguration",
"lambda:AddPermission",
"lambda:UpdateFunctionCode",
"lambda:ListTags",
"lambda:TagResource",
"lambda:UntagResource"
],
"Resource": [
"arn:aws:lambda:eu-central-1:<account-id>:function:search-morling-dev-SearchMorlingDev-*"
]
},
{
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": [
"arn:aws:iam::<account-id>:role/<execution-role>"
]
},
{
"Effect": "Allow",
"Action": [
"cloudformation:DescribeStacks",
"cloudformation:DescribeStackEvents",
"cloudformation:CreateChangeSet",
"cloudformation:ExecuteChangeSet",
"cloudformation:DescribeChangeSet",
"cloudformation:GetTemplateSummary"
],
"Resource": [
"arn:aws:cloudformation:eu-central-1:<account-id>:stack/search-morling-dev/*",
"arn:aws:cloudformation:eu-central-1:aws:transform/Serverless-2016-10-31"
]
},
{
"Effect": "Allow",
"Action": [
"apigateway:POST",
"apigateway:PATCH",
"apigateway:GET"
],
"Resource": [
"arn:aws:apigateway:eu-central-1::/restapis",
"arn:aws:apigateway:eu-central-1::/restapis/*"
]
},
{
"Effect": "Allow",
"Action": [
"apigateway:POST",
"apigateway:GET"
],
"Resource": [
"arn:aws:apigateway:eu-central-1::/usageplans",
"arn:aws:apigateway:eu-central-1::/usageplans/*",
"arn:aws:apigateway:eu-central-1::/apikeys",
"arn:aws:apigateway:eu-central-1::/apikeys/search-morling-dev-apikey"
]
}
]
}Perhaps this could be trimmed down some more, but I felt it’s good enough for my purposes.
Performance
At this point I haven’t conducted any systematic performance testing yet. There’s definitely a significant difference in terms of latency between running things locally on my (not exactly new) laptop and on AWS Lambda. Where the app starts up in ~30 ms locally, it’s ~180 ms when deployed to Lambda. Note this is only the number reported by Quarkus itself, the entire cold start duration of the application on Lambda, i.e. including the time required for fetching the code to the execution environment and starting the container, is ~370 ms (with 256 MB RAM assigned). Due to the little trick described above, though, a visitor is very unlikely to ever experience this delay when executing a query.
Similarly, there’s a substantial difference in terms of request execution duration. Still, when running a quick test of the deployed service via Siege, the vast majority of Lambda executions clocked in well below 100 ms (depending on the number of query hits which need result highlighting), putting them into the lowest bracket of billed Lambda execution time. As I learned, Lambda allocates CPU resources proportionally to assigned RAM, meaning assigning twice as much RAM should speed up execution, also if my application actually does not need that much memory. Indeed, with 512 MB RAM assigned, Lambda execution is down to ~30 - 40 ms after some warm-up, which is more than good enough for my purposes.
Raw Lambda execution of course is only one part of the overall request duration, on top of that some time is spent in the API Gateway and on the wire to the user; The service is deployed in the AWS eu-central-1 region (Frankfurt, Germany), yielding roundtrip times for me, living a few hundred km away, between 50 - 70 ms (again with 512 MB RAM). With longer distances, network latencies outweigh the Lambda execution time: My good friend Eric Murphy from Seattle in the US reported a roundtrip time of ~240 ms when searching for "Java", which I think is still quite good, given the long distance.
Cost Control
The biggest issue for me as a hobbyist when using pay-per-use services like AWS Lambda and API Gateway is cost control. Unlike typical enterprise scenarios where you might be willing to accept higher cost for your service in case of growing demand, in my case I’d rather set up a fixed spending limit and shut down my search service for the rest of the month, once that has been reached. I absolutely cannot have an attacker doing millions and millions of calls against my API which could cost me a substantial amount of money.
Unfortunately, there’s no easy way on AWS for setting up a maximum spending after which all service consumption would be stopped. Merely setting up a budget alert won’t cut it either, as this won’t help me while sitting on a plane for 12h (whenever that will be possible again…) or being on vacation for three weeks. And needless to say, I don’t have an ops team monitoring my blog infrastructure 24/7 either.
So what to do to keep costs under control? An API usage plan is the first part of the answer. It allows you to set up a quota (maximum number of calls in a given time frame) which is pretty much what I need. Any calls beyond the quota are rejected by the API Gateway and not charged.
There’s one caveat though: a usage plan is tied to an API key,
which the caller needs to pass using the X-API-Key HTTP request header.
The idea being that different usage plans can be put in place for different clients of an API.
Any calls without the API key are not charged either.
Unfortunately though this doesn’t play well with CORS preflight requests as needed in my particular use case.
Such requests will be sent by the browser before the actual GET calls to validate that the server actually allows for that cross-origin request.
CORS preflight requests cannot have any custom request headers, though,
meaning they cannot be part of a usage plan.
The AWS docs are unclear whether those preflight requests are charged or not,
and in a way it seems unfair if they were charged given there’s no way to prevent this situation.
But at this point it is fair to assume they are charged and we need a way to prevent having to pay for a gazillion preflight calls by a malicious actor.
In good software developer’s tradition I turned to Stack Overflow for finding help, and indeed I received a nice idea: A budget alert can be linked with an SNS topic, to which a message will be sent once the alert triggers. Then another Lambda function can be used to set the allowed rate of API invocations to 0, effectively disabling the API, preventing any further cost to pile up. A bit more complex than I was hoping for, but it does the trick. Thanks a lot to Harish for providing this nice answer on Stack Overflow and his blog! I implemented this solution and sleep much better now.
Note that you should set the alert to a lower value than what you’re actually willing to spend, as billing happens asynchronously and requests might come in some more time until the alert triggers: as per Corey Quinn, there’s an "8-48 hour lag between 'you incur the charge' and 'it shows up in the billing system where an alert can see it and thus fire'". It’s therefore also a good idea to reduce the allowed request rate. E.g. in my case I’m not expecting really that there’d be more than let’s say 25 concurrent requests (unless this post hits the Hackernews front page of course), so setting the allowed rate to that value helps to at least slow down the spending until the alert triggers.
With these measures in place, there should (hopefully!) be no bad surprises at the end of the month. Assuming a (very generously estimated) number of 10K search queries per month, each returning a payload of 5 KB, I’d be looking at an invoice over EUR 0.04 for the API Gateway, while the Lambda executions would be fully covered by the AWS free tier. That seems manageable :)
Wrap-Up and Outlook
Having rolled out the search feature for this blog a few days ago, I’m really happy with the outcome. It was a significant amount of work to put everything together, but I think a custom search is a great addition to this site which hopefully proves helpful to my readers. Serverless is a perfect architecture and deployment option for this use case, being very cost-efficient for the expected low volume of requests, and providing a largely hands-off operations experience for myself.
With AOT compilation down to native binaries and enabling frameworks like Quarkus, Java definitely is in the game for building Serverless apps. Its huge eco-system of libraries such as Apache Lucene, sophisticated tooling and solid performance make it a very attractive implementation choice. Basing the application on Quarkus makes it a matter of configuration to switch between creating a deployment package for Lambda and a regular container image, avoiding any kind of lock-in into a specific platform.
Enabling libraries for being used in native binaries can be a daunting task, but over time I’d expect either library authors themselves to do the required adjustment to smoothen that experience, and of course the growing number of Quarkus extensions also helps to use more and more Java libraries in native apps. I’m also looking forward to Project Leyden, which aims at making AOT compilation a part of the Java core platform.
The deployment to AWS Lambda and API Gateway was definitely more involved than I had anticipated; things like IAM and budget control are more complex than I think they could and should be. That there is no way to set up a hard spend capping is a severe shortcoming; hobbyists like myself should be able to explore this platform without having to fear any surprise AWS bills. It’s particular bothersome that API usage plans are no 100% safe way to enforce API quotas, as they cannot be applied to unauthorized CORS pref-flight requests and custom scripting is needed in order to close this loophole.
But then this experiment also was an interesting learning experience for me; working on libraries and integration solutions most of the time during my day job, I sincerely enjoyed the experience of designing a service from the ground-up and rolling it out into "production", if I may dare to use that term here.
While the search functionality is rolled out on my blog, ready for you to use, there’s a few things I’d like to improve and expand going forward:
-
CI pipeline: Automatically re-building and deploying the search service after changes to the contents of my blog; this should hopefully be quite easy using GitHub Actions
-
Performance improvements: While the performance of the query service definitely is good enough, I’d like to see whether and how it could be tuned here and there. Tooling might be challenging there; where I’d use JDK Flight Recorder and Mission Control with a JVM based application, I’m much less familiar with equivalent tooling for native binaries. One option I’d like to explore in particular is taking advantage of Quarkus bytecode recording capability: bytecode instructions for creating the in-memory data structure of the Lucene index could be recorded at build time and then just be executed at application start-up; this might be the fastest option for loading the index in my special use case of a read-only index
-
Serverless comments: Currently I’m using Disqus for the commenting feature of the blog. It’s not ideal in terms of privacy and page loading speed, which is why I’m looking for alternatives. One idea could be a custom Serverless commenting functionality, which would be very interesting to explore, in particular as it shifts the focus from a purely immutable application to a stateful service that’ll require some means of modifiable, persistent storage
In the meantime, you can find the source code of the Serverless search feature on GitHub. Feel free to take the code and deploy it to your own website!
Many thanks to Hans-Peter Grahsl and Eric Murphy for their feedback while writing this post!