
Logical replication allows you to capture and propagate all the data changes from a Postgres database in real-time. Not only is it widely used for replication within Postgres clusters, thanks to the well documented protocol, also non-Postgres tools can tap into the replication data stream and leverage it for heterogeneous replication pipelines across system boundaries. With the help of logical replication clients such as the Debezium connector for Postgres, you can transfer data from your operational database into data warehouses, data lakes, or search indexes, typically with (sub-)second end-to-end latencies.
But logical replication has its quirks, too.
Besides WAL pile-up caused by inactive replication slots
(something I’ve written about here),
one common stumbling stone is the specific way of how TOAST (The Oversized-Attribute Storage Technique) columns are handled by logical replication.
TOAST is Postgres' way of dealing with large column values:
if a tuple (the physical representation of a row in a Postgres table) is larger than two kilobytes, large column values will be split up into several tuples, spread across multiple database pages.
Such large values are commonly found when dealing with unstructured text, or when storing non-textual media blobs,
for example for multi-modal AI use cases.
For each table with TOAST-able column types (for instance, text and bytea), an associated TOAST table will be created for storing these out-of-line values.
Now, how does all that relate to logical replication?
The answer to this depends on the replica identity configured for a given table.
Specifically, unless a table has replica identity FULL
(which isn’t always desirable due to the impact on WAL size and CPU consumption),
if a row in that table gets updated,
logical replication will expose a TOAST-ed field only if its value has changed.
Conversely, unchanged TOAST-ed fields will not have a value provided.
This means that the change events created by a CDC tool such as Debezium don’t completely describe the current state of that row,
which makes them more complex to handle for consumers.
Debezium change events contain a special marker value for unchanged TOAST columns in this situation,
__debezium_unavailable_value.
|
You might wonder why this relatively generic sentinel value was chosen. The reason is that the value is not only used for representing missing TOAST columns in data change events emitted by the Postgres connector, but for instance also for representing Oracle LOB/BLOB columns in a similar situation. |
A change event consumer supporting partial updates can issue specific update queries which exclude any fields with that marker value.
For example, Snowflake lets you do this through MERGE queries with a CASE clause.
This approach isn’t ideal for a number of reasons, though.
It requires the consumer to be aware of the fact that specific columns are TOAST-able,
and it needs to have that information for each affected column of each affected table.
Worse, if there are multiple consumers, each and every one of them will have to implement that logic.
Finally, not all downstream systems may allow for partial updates to begin with,
only letting you update entire records at once.
Taking a step back, the underlying problem is that we are leaking an implementation detail here, requiring consumers to deal with something they shouldn’t really have to care about. It would be much better to solve this issue at the producer side, establishing a consciously designed data contract which shields consumers from intricacies like TOAST columns. Moving this sort of processing closer to the source of a data pipeline ("Shift Left"), helps to create reusable data products which are easier to consume, without having to reinvent the wheel in every single consumer, be it a data warehouse, data lake, or a search index.
In the remainder of this post I’d like to discuss several techniques for doing exactly that: Debezium’s built-in solution—column reselects—as well as stateful stream processing with Apache Flink.
Debezium Reselect Postprocessor
While Debezium by default exports the __debezium_unavailable_value sentinel value for unchanged TOAST-ed fields for tables with default replica identity,
it provides some means to improve the situation.
A post processor is available that queries the source database to retrieve the current value of the affected field, updating the change event with that value before it’s emitted.
To set up the post processor, add the following to your Debezium connector configuration:
1
2
3
4
5
6
7
8
9
10
11
{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
...
"post.processors": "reselector",
"reselector.type":
"io.debezium.processors.reselect.ReselectColumnsPostProcessor", (1)
"reselector.reselect.columns.include.list":
"inventory.authors:biography", (2)
"reselector.reselect.unavailable.values": "true",
"reselector.reselect.null.values" : "false"
}
| 1 | Enable the column reselect post processor for the events emitted by this connector |
| 2 | Query missing values for the biography column of the inventory.authors table |
This may do the trick in certain situations, in particular if a TOAST-ed column rarely or even never changes.
There are some important implications, though.
Most importantly, the solution is inherently prone to data races:
If there are multiple updates to a row in quick succession and the TOAST-ed column changes,
an earlier change event may be enriched with the latest value of the column.
This may happen as Postgres does not support queries for past values
(Debezium implements a more robust solution for Oracle using an AS OF SCN query).
Longer delays between creating a change event in the database and processing it with Debezium—for instance in case of a connector downtime—exacerbate that problem.
Furthermore, there may be a performance impact: running a query for every event adds latency, and it may impose undesired load onto the source database, in particular considering that currently there’s no batching applied for these look-ups. When using the reselect post processor, you should make sure to run Debezium close to your database, in order to minimize the latency impact.
Issuing a database query for getting the current value of a TOAST-ed column isn’t ideal. Rather, we’d want to retrieve the column value exactly as it was when that update happened, ideally also offloading these look-ups to a separate system. This kind of processing is a prime use case for stateful stream processors such as Apache Flink. So let’s explore how we could implement TOAST column backfills using Flink.
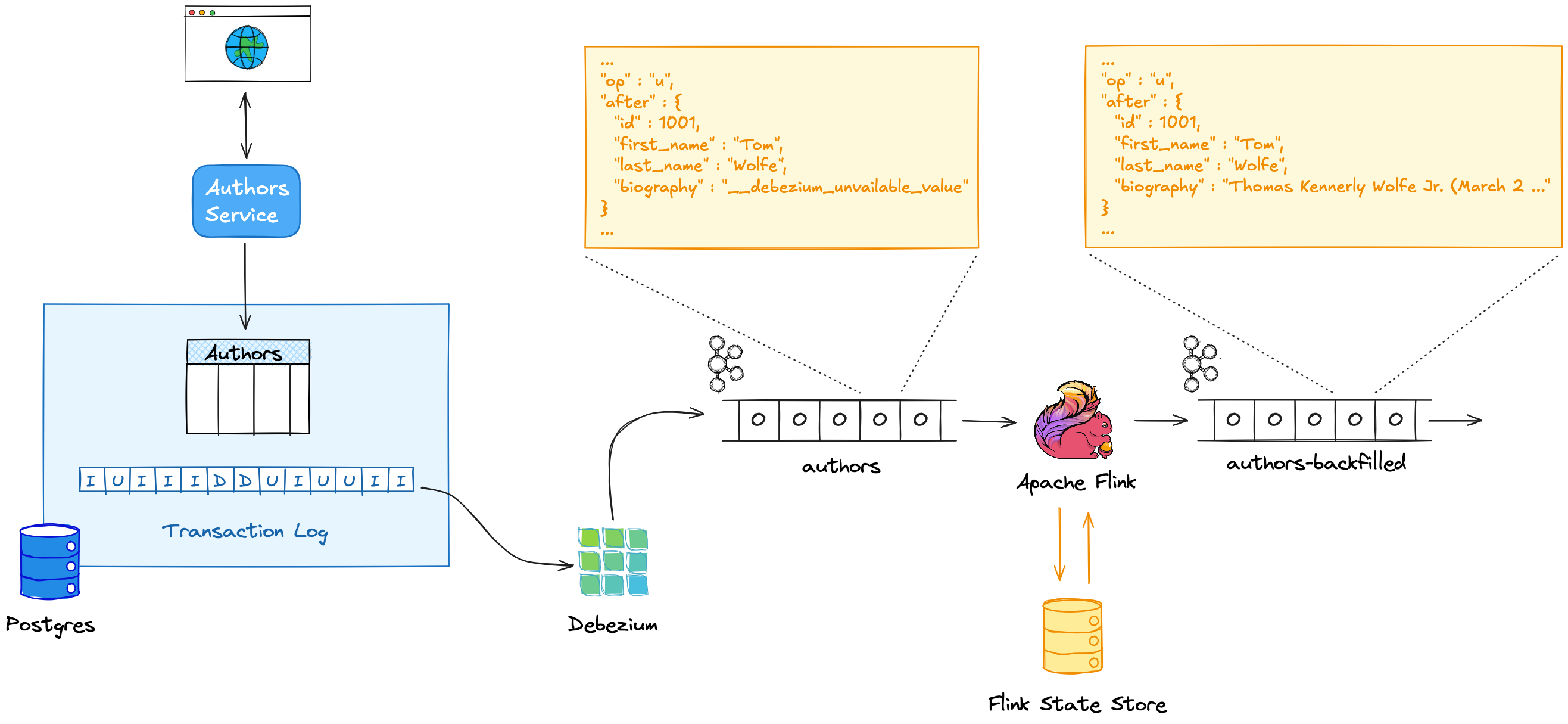
Flink DataStream API
Flink supports several APIs for implementing stream processing jobs which differ in terms of their complexity and the capabilities they offer. The DataStream API is a foundational API which provides you with the highest degree of freedom and flexibility, at the same time it has a steep learning curve and you can shoot into your own foot easily.
To implement a backfill of TOAST columns, we’ll need to create a custom processing function which manages the column values through a persistent state store.
It puts the value into the state store when processing an insert change event,
and later on, it’ll read it back to replace the sentinel value in update events which don’t modify the TOAST column.
As the state needs to be managed per record, the KeyedProcessFunction contract must be implemented:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
public class ToastBackfillFunction extends
KeyedProcessFunction<Long, KafkaRecord, KafkaRecord> { (1)
private static final String UNCHANGED_TOAST_VALUE =
"__debezium_unavailable_value";
private final String columnName;
private ValueStateDescriptor<String> descriptor; (2)
public ToastBackfillFunction(String columnName) {
this.columnName = columnName;
}
@Override
public void open(OpenContext openContext) throws Exception {
descriptor = new ValueStateDescriptor<String>(columnName,
String.class); (3)
}
@Override
public void processElement(KafkaRecord in, Context ctx,
Collector<KafkaRecord> out) throws Exception { (4)
ValueState<String> state = getRuntimeContext().getState(descriptor);
Map<String, Object> newRowState =
(Map<String, Object>) in.value().get("after");
switch ((String)in.value().get("op")) {
case "r", "i" ->
state.update((String) newRowState.get(columnName)); (5)
case "u" -> {
if (UNCHANGED_TOAST_VALUE.equals(
newRowState.get(columnName))) { (6)
newRowState.put(columnName, state.value());
} else {
state.update((String) newRowState.get(columnName)); (7)
}
}
case "d" -> {
state.clear(); (8)
}
}
out.collect(in); (9)
}
}
| 1 | This is a keyed process function working on Long keys (the primary key type of our table), consuming and emitting Kafka records mapped via Jackson |
| 2 | Descriptor for a key-scoped value store containing the latest value of the TOAST column |
| 3 | Initialize the state store when the function instance gets created and configured |
| 4 | The processElement() method is invoked for each element on the stream |
| 5 | When receiving an insert or read (i.e. snapshot) event, put the value of the given TOAST column into the state store |
| 6 | When receiving an update event which doesn’t modify the TOAST column, retrieve the value from the state store and put it into the event |
| 7 | When receiving an update event which does modify the column, update the value in the state store |
| 8 | When receiving a delete event, remove the value from the state store |
| 9 | Emit the event |
The function must be applied to a stream which is keyed by the change event’s primary record:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<KafkaRecord> source = ...;
KafkaSink<KafkaRecord> sink = ...;
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
.keyBy(record -> { (1)
return Long.valueOf((Integer) record.key().get("id"));
})
.process(new ToastBackfillFunction("biography")) (2)
.sinkTo(sink);
env.execute("Flink TOAST Backfill");
| 1 | Key the incoming change event stream by the table’s primary key, id |
| 2 | For each change event, apply the TOAST backfill function |
The Kafka source shown in the job reads Debezium data change events from a Kafka topic, whereas the Kafka sink will write them to another topic, once they have been processed. For each record of the source table, the processing function keeps the latest value of the TOAST column in the state store. Depending on the number of records and the size of the TOAST column values, a sizable amount of state will be stored. That’s not a fundamental problem though: Flink jobs commonly manage hundreds of gigabytes of state size, and newer developments like the disaggregated state management in Flink 2.0 can help with that task.
You can find the complete runnable example in my streaming-examples repo on GitHub.
Flink SQL With OVER Aggregation
Besides the DataStream API, Apache Flink also provides a relational interface to stream processing in the form of Flink SQL and the accompanying Table API. This makes stateful stream processing accessible to a much larger audience: all the developers and data engineers who are familiar with SQL. Which begs the question: can TOAST column backfills be implemented with a SQL query? As it turns out, yes it can!
The key idea is to use Flink’s Apache Kafka SQL connector in append-only mode for operating on the "raw" stream of Debezium change events and applying the necessary backfill with an OVER aggregation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
INSERT INTO authors_backfilled
SELECT
id,
before,
ROW(
id,
after.first_name,
after.last_name,
CASE
WHEN after.biography IS NULL THEN NULL
ELSE
LAST_VALUE(NULLIF(after.biography,
'__debezium_unavailable_value')) OVER (
PARTITION BY id
ORDER BY proctime
RANGE BETWEEN INTERVAL '30' DAY PRECEDING AND CURRENT ROW
)
END,
after.dob
),
source,
op,
ts_ms
FROM
authors
Unlike a regular GROUP BY aggregation, which condenses multiple input rows into a single output row,
an OVER aggregation produces an aggregated value for every input row, based on a given window.
The LAST_VALUE() aggregation function propagates the last non NULL value for each window.
By mapping the unavailable value placeholder to NULL using NULLIF(), this will always be the latest value of the biography column.
The data is partitioned by id: the aggregation window are all the change events with the same primary key within the given interval of 30 days.
|
Finding the right value for that look-back period can be tricky, as it depends on the lifecycle of your data. If update events for a record can come in 180 days after the previous update, state in the Flink job must be retained for that entire time. Ideally, we’d dispose of the state for a given record once the delete event for that key has been ingested. Unfortunately, I am not aware of any way for doing so purely with Flink SQL on an append-only data stream. The PTF solution discussed in the next section implements this logic. |
In order to handle the situation where the TOAST-ed column actually is set to NULL, the aggregation is wrapped by a CASE clause which emits the NULL value in this case.
Note that the statement above is simplified somewhat for the sake of comprehensibility.
In particular, it ignores the case of delete events whose after field is null,
which could be implemented using another CASE clause.
Solving the problem solely with SQL makes for a generally elegant and portable solution,
especially when considering that Flink SQL tends to be more widely supported by Flink SaaS vendors than the DataStream API,
due to the inherent complexities of operating the latter.
Yet, it is not a silver bullet:
The complexity of statements can become a problem quickly.
As discussed above, you lack fine-grained control over the retention period of the required state.
Furthermore, SQL arguably has a bit of a discoverability problem,
in particular software engineers with a background in application development may not necessarily be aware of features such as OVER aggregations.
This leads us to the next and final way for backfilling TOAST columns, which combines the simplicity of SQL with the flexibility and expressiveness of implementing key parts of the functionality imperatively.
Flink Process Table Functions
The idea of this approach is to delegate state management to a custom process table function (PTF). Specified in FLIP-440, PTFs are a new kind of user-defined function (UDF) for Flink SQL, which will be available in Flink 2.1. Complementing other types of UDFs already present in earlier Flink SQL versions, such as scalar and aggregate functions, PTFs are much more powerful and have a few very interesting characteristics:
-
Just like a custom process function you’d implement for the DataStream API, they provide you with access to persistent state and timers
-
Unlike scalar functions, they are table-valued functions (TVFs) that accept tables as input and produce a table as output
-
They are also polymorphic functions (in fact, PTFs are called polymorphic table functions in the SQL standard), which means that their input and output types are determined dynamically, rather than statically
The polymorphic nature allows for extremely powerful customizations of your SQL queries, for instance there could be a PTF which exposes the contents of a Parquet file in a typed way, allowing for the projection of specific columns. Other potential use cases for custom PTFs include implementing specific join operators, doing remote REST API calls for enriching your data, integrating with LLMs for sentiment analysis or categorization, and much more.
PTFs are a comprehensive extension to the Flink API and definitely warrant their own blog post at some point, for now let’s just take a look at how to use a PTF for backfilling Postgres TOAST columns. Note that PTFs are still work-in-progress and details of the API may change. The following has been implemented against Flink built from source as of commit f7b5d00.
To create a PTF, create a subclass of ProcessTableFunction, parameterized with the output type.
In our case that’s Row, as this PTF produces entire table rows.
The processing logic needs to be implemented in a method named eval(),
which takes any arguments, and optionally a state carrier object as well as other context, as input:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class ToastBackfillFunction extends ProcessTableFunction<Row> {
private static final String UNCHANGED_TOAST_VALUE =
"__debezium_unavailable_value";
public static class ToastState { (1)
public String value;
}
public void eval(ToastState state, Row input, String column) { (2)
Row newRowState = (Row) input.getField("after");
switch ((String)input.getField("op")) {
case "r", "c" -> { (3)
state.value = (String) newRowState.getField(column);
}
case "u" -> { (4)
if (UNCHANGED_TOAST_VALUE.equals(newRowState.getField(column))) {
newRowState.setField(column, state.value);
} else {
state.value = (String) newRowState.getField(column);
}
}
case "d" -> { (5)
state.value = null;
}
}
collect(input); (6)
}
}
| 1 | A custom state type for managing the persistent state of this PTF; stores the latest value for the given TOAST column |
| 2 | The eval() method will be invoked for each row to be aggregated; it declares the state type and two arguments for PTF: the table to process, and the name of the TOAST column |
| 3 | If the incoming event is an insert (c) or snapshot (r) event, store the value of the specified TOAST column in the state store |
| 4 | If the incoming event is an update and the value of the TOAST column didn’t change, retrieve the value from the state store and update the input row with it; if the value did change, update the value in the state store |
| 5 | If the incoming event is a delete, remove the value for the given key from the state; i.e. in contrast to the OVER aggregation solution,
the state retention time now closely matches the lifecycle of the underlying data itself |
| 6 | Emit the table row |
In most cases, semantics of the arguments of the eval() method can be determined automatically via reflection,
or they can be specified using annotations such as @StateHint and @ArgumentHint.
The TOAST backfill PTF is special in so far as that its output type can’t be specified statically;
instead, it mirrors the type of the table the PTF is applied to.
For dynamic cases like this, the getTypeInference() method can be overridden,
allowing you to declare the exact input and output type semantics for the method:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
LinkedHashMap<String, StateTypeStrategy> stateTypeStrategies =
LinkedHashMap.newLinkedHashMap(1); (1)
stateTypeStrategies.put("state",
StateTypeStrategy.of(
TypeStrategies.explicit(
DataTypes.of(ToastState.class).toDataType(typeFactory))));
return TypeInference.newBuilder()
.staticArguments( (2)
StaticArgument.table( (3)
"input",
Row.class,
false,
EnumSet.of(StaticArgumentTrait.TABLE_AS_SET)),
StaticArgument.scalar("column", DataTypes.STRING(), false) (4)
)
.stateTypeStrategies(stateTypeStrategies) (1)
.outputTypeStrategy(callContext -> (5)
Optional.of(callContext.getArgumentDataTypes().get(0)))
.build();
}
| 1 | Declares the state type of the PTF |
| 2 | Defines the arguments of the PTF |
| 3 | The first argument is the input table; it has "set" semantics, which means the method operates on partitioned sets of rows (as opposed to "row" semantics, in which case it would operate on individual rows of the table); the PTF’s state is managed within the context of each of those partitioned sets; the argument is of type Row (representing a table row) and it is not optional |
| 4 | The second argument is the name of the TOAST column to process; it is of type String and also not optional |
| 5 | The output type is exactly the same as the row type of the input table |
With that PTF definition in place, it can be invoked like this:
1
2
3
4
5
6
7
8
9
10
INSERT INTO authors_backfilled
SELECT
id,
before,
after,
source,
op,
ts_ms
FROM
ToastBackfill(TABLE authors PARTITION BY id, "biography"); (1)
| 1 | Invoke the PTF for the authors table, partitioned by id, and backfilling values for the biography TOAST column |
Invoking a table-valued function might feel unusual at first,
but on the upside the overall statement is quite a bit less complex than the OVER aggregation shown above.
This illustrates another potential benefit of PTFs:
they let you encapsulate that logic in a reusable function,
thus allowing for less complex and verbose queries.
You might develop a library of parameterized PTFs tailored to your specific use cases,
ready to be used by the data engineers in your organization for building streaming pipelines.
Summary and Discussion
Used for storing large values, Postgres TOAST columns are not fully represented in data change events for tables without replica identity FULL.
As such, they create complexities for downstream consumers,
which typically are better off with events describing the complete state of a row.
In this post, we’ve explored several solutions to address this issue.
Debezium’s built-in reselect post processor queries the database for missing values.
It can be a solution for simple cases, but it is prone to data races and can create performance issues.
Stateful stream processing, using Apache Flink, is a powerful alternative.
Flink provides multiple options for solving this task, ranging from a purely imperative solution using the DataStream API,
over a purely SQL-based implementation in form of an OVER aggregation,
to a hybrid solution with a custom process table function for state management, invoked from within a very basic SQL query.
To be officially released with Flink 2.1 later this year, the PTF approach strikes a very appealing balance between expressiveness and flexibility—for instance in regards to managing the lifecycle of TOAST backfill data in the Flink state store—and ease of use for authors of SQL queries.
Now, could Debezium also provide a reliable and robust solution out of the box, thus eliminating the need for any subsequent processing? Indeed I think it could: Next to the existing re-select post processor, there could be another one which implements the backfilling logic described in this post. To do so, such a post processor could directly manage values in a persistent store such as RocksDB or SlateDB. Alternatively, it also could embed Flink into the connector process, using Flink’s mini-cluster deployment mode. I’ve logged issue DBZ-9078 for exploring this further; please reach out if this sounds interesting to you!
Many thanks to Andrew Sellers, Renato Mefi, and Steffen Hausmann for their feedback while writing this post!