
A while ago, Seth Wiesman did an excellent talk at Kafka Summit titled "OH: That microservice should have been a SQL query". In this presentation he made the case for implementing microservices as SQL queries on top of a stream processor, arguing that this approach yields faster times to market, while ensuring high consistency, scalability, and low latency for your data processing. This story resonated a lot with me, considering that stream processing jobs really are an exemplification of the microservices idea: do one thing, and do it well.
This got me thinking: can the same line of argument be made for building agentic systems? Would it be a good idea to build an AI Agent as a streaming SQL query? And if so, what would it take to do so? Before running this thought experiment, let’s define what we mean when talking about AI Agents. I like Google’s no fluff definition quite a bit:
AI agents are software systems that use AI to pursue goals and complete tasks on behalf of users. They show reasoning, planning, and memory and have a level of autonomy to make decisions, learn, and adapt.
Another, rather pragmatic way to look at this is to think of AI Agents as microservices, which take some kind of input, process that input, with an AI model, typically a large language model (LLM), and emit the result. This is to say, compared to some lofty ideas of what an AI Agent could be and what it could do ("Here’s my AWS access key, go and cut my cloud spend into half!"), most of the agents people actually deploy at this point are relatively firmly defined AI-assisted workflows (in fact, in their widely received article Building effective agents, the Anthropic team is categorizing agentic systems into workflows and agents). Potential use cases include customer service interactions, document processing in healthcare, automated sales processes, predictive maintenance processes, and others.
Now, why could it be interesting to build AI Agents in the form of streaming jobs, specifically as SQL queries? It might sound a bit like an odd idea at first, but I think it actually warrants some consideration.
|
When issuing a SQL query in a traditional database, results are determined in a pull approach, i.e. the query is run against the underlying dataset (by scanning tables, querying indexes, etc.) and the entire result set is returned to the client. Streaming query systems reverse this pattern. Queries are running continuously and compute results incrementally, in a push based way. If there is a change to the dataset, only the affected records are processed by the query, and the corresponding delta to the query’s result set is emitted to clients. |
At their core, stream processors like Apache Flink are a platform for building event-driven data-intensive applications, with a strong focus on high performance, scalability, and robustness. As such, they provide many of the building blocks needed for implementing AI Agents, too. Using SQL makes building agents a possibility not only to application developers, but also to all the SQL-savvy data engineers out there.
Based on this premise, let’s discuss a few aspects you should keep in mind in order to build an AI Agent successfully, and whether Apache Flink, as an example of a widely used stream processing engine, and Flink SQL in particular, can be a useful foundation for doing so.
Agents Need to Interact With LLMs
While there are many opinions about what AI Agents really are, one thing is for sure: they need to interact with LLMs. Instead of the traditional way of building software which processes data according to some predefined rules, typically yielding a deterministic outcome, LLM-based systems are less pre-defined. Input data, structured and unstructured, and context such as conversation history is passed as natural language to the LLM, which produces a response in natural language (potentially wrapped in a structured container such as a JSON document to simplify further processing). This output then either is emitted as the result to the caller, or it serves as input for further LLM interactions. In agent-to-agent scenarios, it may also be passed on as the input to another AI Agent.
So how does Flink fare in that regard? Can you interact with ML/AI models from within your streaming SQL queries? Indeed you can. FLIP-437 ("Support ML Models in Flink SQL") aims at making models first class citizens in streaming applications. A new DDL statement CREATE MODEL allows for the registration of AI models from providers such as OpenAI, Google AI, AWS Bedrock, and others.
As an example, let’s assume we’d like to stay on top of new research papers around databases and data streaming from conferences such as VLDB. As reading all the papers can be quite time-consuming, let’s build an agent which summarizes given papers, a task for which LLMs come in really handy. Here’s how a solution for this problem could look like, running on a fully managed stream processing platform such as Confluent Cloud:
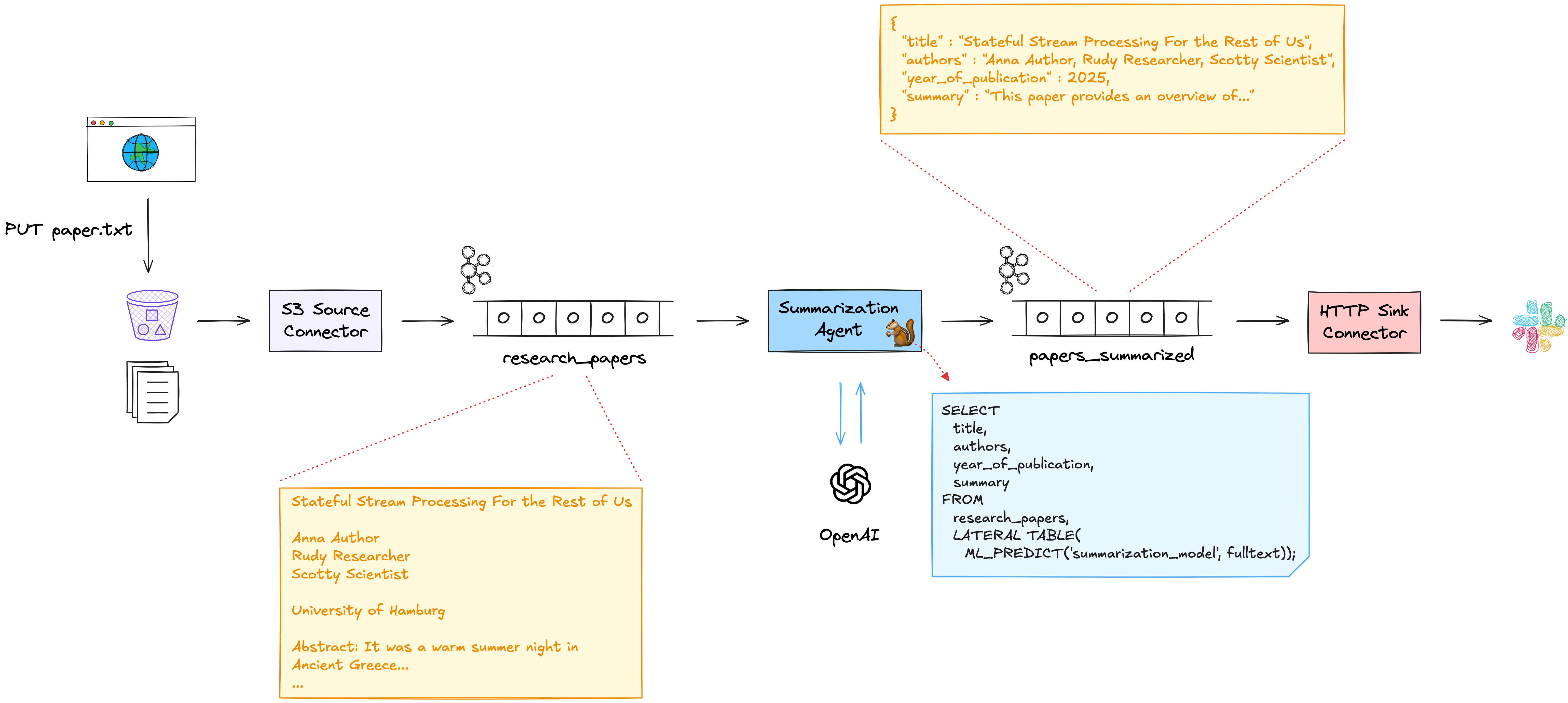
New papers are uploaded to some S3 bucket (for instance using Apache Tika to extract the text from the original PDF files), where they are picked up from an S3 source connector and submitted to a Kafka topic. The agent, implemented as a streaming SQL query, creates a summary for each new paper with the help of an OpenAI model. The result is written to another topic, for instance allowing to push the summary of each new paper into some Slack channel. Here’s how the model can be creation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
CREATE MODEL summarization_model
INPUT(text STRING)
OUTPUT(title STRING, authors STRING, year_of_publication INT,
summary STRING)
COMMENT 'Research paper summarization model'
WITH (
'provider' = 'openai',
'task' = 'text_generation',
'openai.connection' = 'openai-connection',
'openai.model_version' = 'gpt-4.1-mini',
'openai.output_format' = 'json',
'openai.system_prompt' =
'This is a text extract of a research paper in PDF format. ↩
Provide its title, authors, year of publication, and a summary ↩
of 200 to 400 words. Reply with a JSON structure with the fields ↩
"title", "authors", "year_of_publication", "summary". Return ↩
only the JSON itself, no Markdown mark-up.'
);
Note how that model definition also contains the system prompt to be used. The FLIP still is work-in-progress in the Flink open-source project, but it already is supported by some Flink-based offerings, including Confluent Cloud for Apache Flink. Once you have defined a model, you can query it via the ML_PREDICT() function (see FLIP-525 for more details). For instance like so, querying the summarization model above:
1
2
3
4
5
6
INSERT INTO papers_summarized
SELECT
fulltext, title, authors, year_of_publication, summary
FROM
research_papers,
LATERAL TABLE(ML_PREDICT('summarization_model', fulltext));
Once this query is running, a new paper pushed to the input topic, research_papers, will yield a result like this on the papers_summarized topic:
1
2
3
4
| fulltext | title | authors | year_of_publication | summary |
+----------------------------------------------+------------------------+---------------------------------------------+---------------------+------------------------------------------------+
| Styx: Transactional Stateful Functions on... | Styx: Transactional... | Kyriakos Psarakis, George Christodoulou,... | 2025 | This paper introduces Styx, a novel runtime... |
| ... | ... | ... | ... | ... |
In this example we’re using an LLM for summarizing the elements of a data stream, but you could also follow the same approach for sentiment analysis, categorizing data, creating recommendations, detecting spam, translating text, and much more.
Agents Should Be Event-Driven
When thinking of agentic AI, conversational agents—based on synchronous request-response patterns—may be the first thing coming to mind, with a ubiquitous example being LLM-backed chatbots. At this point, probably everyone has communicated with LLMs that way, either directly by using tools like ChatGPT or Claude, or indirectly by talking to chatbots on the website of an ecommerce platform or an airline.
Arguably though, in an enterprise context, autonomous event-driven agents oftentimes are more relevant. Based on real-time data and event streams, such as user interactions in a web shop, sensor data from a wind turbine, or changes in some database, such agents take intelligent action without user intervention, for instance to restock inventory, issue a predictive repair order, etc. An event-driven agent performs its job not when a human happens to engage with it, but when the input data requires it. The result typically will be another type of event, either consumed asynchronously as input by other AI agents, as a command by traditional non-agentic systems, or by a human for validation and approval.
This sort of event-driven data processing is an absolute sweet spot for Flink SQL, and Flink in general. Its large ecosystem of ready-made connectors provides integration with a wide range of source and sink systems, data stores, and services. Clickstream data via Kafka, change data feeds from your database, sensor measurements via MQTT—There’s connectors pretty much for everything.
While Flink lets you run connectors directly embedded into the stream processing engine, in particular the combination with an event streaming platform such as Apache Kafka opens up many interesting possibilities. This approach allows you to create networks of specialized loosely coupled agents, which can build on each other’s results, without having to know details like where a given agent runs. Kafka connects and unlocks your company’s systems, teams, and databases, providing agents with the context they need to operate and provide value on top of your organization’s proprietary data. Thanks to Flink’s unification of stream and batch processing, agents can not only react to incoming events in real-time, but—with the right retention policy for your Kafka topics—they also can reprocess a stream of input data if needed. This is not only very useful for the purposes of failure recovery, but also for testing and validating changed processing logic after updating an agent. In an A/B testing scenario, two different variants of the same agent could process the same set of input topics, allowing you to compare the different outcomes and evaluate which one performs better.
Finally, an event-driven architecture also helps to overcome an inherent limitation of LLMs: they are fixed in time. Their knowledge is subject to the cutoff date of their training dataset. With a RAG-based approach (retrieval-augmented generation), as discussed in the next section, additional data can be fed to a model at inference time. Ingesting new or changed data in real-time into a vector store helps to make the latest and up-to-date information available to the LLM.
Agents Need Context
LLMs are general-purpose models created from huge bodies of publicly available datasets. However, many, if not most, AI Agents for enterprise use cases require access to context such as internal data and resources, tools and services. How can this be implemented when building an agentic system using Flink SQL?
First, let’s consider the case of structured data, for instance details about a given customer stored in an external database. SQL is a natural fit for accessing that kind of data: Flink SQL allows you to enrich the data to be sent to an LLM using SQL join semantics. One option is to join streams sourced from one of the wide range of source connectors (and by extension, also using the Kafka Connect source connector ecosystem). Alternatively, in particular for reference data which doesn’t frequently change, you also can use look-up joins, which let you retrieve data from external data sources, such as databases or CRM systems. In that case, Flink will take care of caching look-up results in a local RocksDB instance for the sake of efficiency, fetching data from the upstream source only when needed.
When it comes to feeding non-public unstructured data—documentation and wiki pages, reports, knowledgebases, customer contracts, etc.—to an LLM, retrieval-augmented generation (RAG) is a proven solution. With the help of a language model, unstructured domain-specific information is encoded into embeddings, which are stored in a vector database such as Pinecone or Elasticsearch, or alternatively using a vector index of a more traditional data store like Postgres or MongoDB. Thanks to Flink SQL’s rich type system, vectors are natively supported as ARRAY<FLOAT>. When an agent is about to make a query to an LLM, the input data is used to query the vector store, allowing the agent to enrich the LLM prompt with relevant domain-specific information, yielding higher quality results, based on the latest data and information of your specific business context.
What does that mean for our thought experiment of building AI Agents as Flink SQL queries? Following up on the example of summarizing research papers, let’s assume we’re also doing company-internal research, the results of which are documented in an internal wiki. Based on the summary of an incoming research paper, we’d like to identify relevant internal research and get some understanding of the relationship between the new paper and our own research, for instance providing new angles and perspectives for future research activities. To solve that task, we could think of having two streaming SQL jobs, which both taken together form an agentic system:
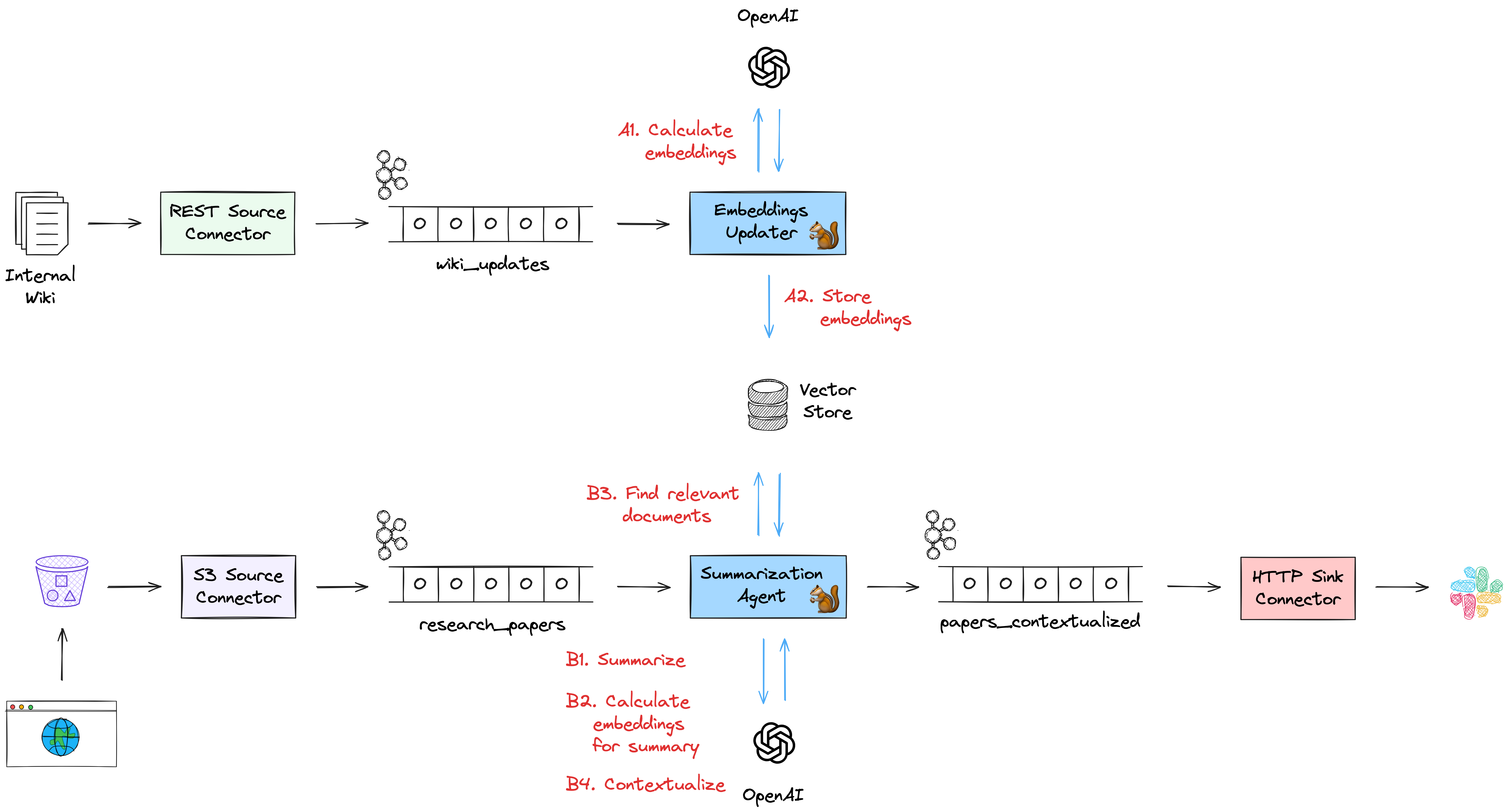
One job creates and updates the embeddings in the vector store, whenever there’s a change in the internal research wiki. In other scenarios, thanks to the rich eco system of Flink connectors, the data could also be retrieved in real-time from a relational database using change data capture, through a web hook which receives a notification after changes to a company’s wiki pages, etc. To create the vector embeddings (A1), the ML_PREDICT() function can be used with an embedding model such as OpenAI’s text-embedding-3-small model. That way, the embedding representation in the vector store is continuously kept in sync with the original data (A2).
In the actual agent job itself, we’d create a summary of each new paper as described above (B1). Next, we’d use ML_PREDICT() with the same embedding model for creating a vector representation of that summary (B2). This embedding then is used to query the vector store and identify the most relevant internal research documents, for instance based on cosine similarity (B3). Currently, there’s no support for this built into Apache Flink itself, so this is something you’d have to implement yourself with a user-defined function (UDF). When running on Confluent Cloud, there’s a ready-made function VECTOR_SEARCH(), which lets you execute queries against different vector stores; eventually, I’d expect this capability to also be available in upstream Flink. Finally, we’d use the results to augment another LLM invocation via ML_PREDICT() for establishing the relationship between the new paper and our own research (B4).
Arguably, so far we’ve stayed on the workflow side of the workflow/agent dichotomy mentioned initially. For building a true AI Agent, it may be necessary to let the LLM itself decide which resources or tools to tap into for a given prompt. Anthropic’s MCP standard (Model Context Protocol) has seen a massive uptake over the last few months for exactly this use case, allowing you to integrate custom services and data sources into your agentic workflows.
Unfortunately, as of today, this is not something which is supported by Flink SQL out-of-the-box. But you can close this gap by implementing a UDF. In particular, Process Table Functions (PTF, defined by FLIP-440), a new kind of UDF available in Flink 2.1 come in very handy for this purpose. They allow you to integrate arbitrary logic written in Java into your SQL pipelines, which means you could build a PTF for the integration of external tools via MCP, for instance using the LangChain4j API.
|
PTFs allow for very flexible customizations of the processing logic of Flink SQL jobs. The integration of MCP into a PTF may be a subject for a future post; in the mean time, refer to this post for taking a first look at using PTFs in the context of a change data capture pipeline for Postgres. |
As PTFs are table valued functions, they can not only operate on single rows and events, but also on groups of rows, for instance all the events pertaining to a specific customer or workflow instance. This makes them a candidate for implementing agent memory; more on that in the following.
Agents Require Memory
Finally, let’s discuss the aspect of state when it comes to building AI Agents. When processing an incoming event, it may be necessary to look back at previous events when assembling the prompt for an LLM. In our research example, this may be previous papers of the same author. In a recommendation use case, this could for instance be all the purchase orders of the customers in a given segment. In a conversational scenario, this might be all the previous messages, requests and responses, in a given conversation.
While Flink SQL manages state for different kinds of query operators (for instance, for windowed aggregations or joins), SQL by itself doesn’t give you the level of fine-grained state access you’d need to model the memory of an AI Agent. The aforementioned process table functions can help with that, though. When applying a PTF to partitioned input streams, you can manage arbitrary state in the context of individual partitions, such as all the events and messages pertaining to a given instance of an AI-based workflow, including previous LLM responses. You could then retrieve these messages from the state store when building the LLM prompt. In that light, a PTF backed by Flink state can be considered as a form of durable execution, tracking the progress of a long-running operation in persistent, resumable form. As a bonus, Flink automatically takes care of distributing that state in a cluster, allowing you to scale out stateful AI Agents to as many compute nodes as needed.
When SQL Is Not Enough
So, it seems we can use Flink SQL for building agentic systems, be it workflows or agents; but does this also mean we should? Are we at risk that—with that squirrely hammer in our hand—every problem is looking like a nail?
Relatively uncontroversially, SQL is great for all kinds of pre- and post-processing of the (structured) data consumed and created by an agent: filtering and transforming data, joining multiple streams, aggregating and grouping data is the sweet spot of a stream processing engine like Flink SQL. It offers tools such as the very powerful MATCH_RECOGNIZE() operator, which lets you search for specific patterns in your input data streams to identify records relevant for further processing. All that on top of a highly scalable, fault-tolerant and battle-proven runtime. But as we’ve seen, it’s also possible to bridge the world to unstructured data processing in natural language, using LLMs, relatively easily. Thanks to recent additions such as built-in model support, LLMs can be integrated into event-driven streaming pipelines, also providing tools like PTFs for managing context and state, integration of MCP, and more.
|
This post explores the implementation of agentic systems in the form of streaming SQL jobs. Another facet to this discussion is how AI Agents can interact with data streaming infrastructure as part of their business logic, for instance in order to identify relevant topics on a Kafka cluster and retrieve data from them, issue Flink streaming queries, etc. The community has been working on several MCP servers for this purpose, including mcp-kafka and mcp-confluent, which enables the integration of Confluent Cloud resources into agentic workflows. |
But what if you want to build an AI Agent which requires some more, well, agency? At some point, you may need to go beyond what’s reasonably doable with a SQL-based implementation. Would it still make sense then to use Flink (instead of Flink SQL), as a runtime for AI Agents? The community seems to think so, considering the recent announcement of the Flink Agents sub-project (FLIP-531).
A collaboration between engineers from Confluent and Alibaba, this project proposal aims at the creation of a Flink-based runtime for AI Agents. The idea is to re-use Flink’s proven foundation for low-latency continuous data processing, which offers many desirable traits such as fault tolerance, scalability, state management, observability, and more. The FLIP seeks to explore a new easy-to-use agent framework on top of that, making AI Agents a first class citizen in the Flink ecosystem. Besides Java, Python support is envisioned, allowing agent authors to tap into the vast ecosystem of AI-related Python libraries. The agent SDK will provide out-of-the-box integration of external tools via MCP, vector search, agent-to-agent communication, etc. In particular that last aspect might trigger some memories of an earlier, now dormant, project under the Flink umbrella: Stateful Functions (StateFun). It remains to be seen whether this will see a revival in the form of an agentic runtime as part of the work on this FLIP.
Parting Thoughts
Apache Flink, with its robust stream processing capabilities and evolving AI integrations, is a compelling and versatile platform for building intelligent, event-driven agentic systems. While some more work needs to be done—for instance around the integration of external tools and resources via MCP—to bridge the gap between agentic workflows and true AI Agents, Flink provides you with the essential tools for connecting to all kinds of event streams and data sources in real-time, LLM integration, context and state management, and much more.
To me, the appeal of using SQL in particular for building agentic systems in a declarative way lies in its notion of democratization: with the right building blocks—for instance, ready-made UDFs for invoking tools via MCP—everyone familiar with SQL can build agentic solutions and put them into production on one of the available fully managed services for Apache Flink. To automate parts of their own personal workflows, but also to create reusable workflows and agents for others.
So, coming back to the original premise of this post—Is this all to say that you should build all your AI Agents using Apache Flink, or Flink SQL? Certainly not. But can it be a very solid foundation for certain cases? Absolutely!
Many thanks to everyone who provided their input and feedback while writing this post, including Joydeep Bhattacharya, Brandon Brown, Steffen Hoellinger, and Michael Noll!