
Over the last couple of years, I’ve helped dozens of users and organizations to build Change Data Capture (CDC) pipelines for their Postgres databases. A key concern in that process is setting up and managing replication slots, which are Postgres' mechanism for making sure that any segments of the write-ahead log (WAL) of the database are kept around until they have been processed by registered replication consumers.
When not being careful, a replication slot may cause unduly large amounts of WAL segments to be retained by the database. This post describes best practices helping to prevent this and other issues, discussing aspects like heartbeats, replication slot failover, monitoring, the management of Postgres publications, and more. While this is primarily based on my experience of using replication slots via Debezium’s Postgres connector, the principles are generally applicable and are worth considering also when using other CDC tools for Postgres based on logical replication.
Use the pgoutput Logical Decoding Output Plug-in
Postgres uses logical decoding output plug-ins for serializing the data sent to logical replication clients. When creating a replication slot, you need to specify which plug-in to use. While several options exist, I’d recommend using the pgoutput plug-in, which is the standard decoding plug-in also used for logical replication between Postgres servers. It has a couple of advantages:
-
pgoutput is available out-of-the-box with Postgres 10+ (including AWS, GCP, and Azure managed services), requiring no additional installation
-
Compared to other plug-ins using JSON as a serialization format, pgoutput uses the efficient binary Postgres replication message format.
-
It provides fine-grained control over the replicated tables, columns, and rows (see further down for more information)
When using CDC tools like Debezium, they’ll typically create the replication slot automatically.
In order to manually create a slot using the pgoutput plug-ing,
call the pg_create_logical_replication_slot() function like so:
1
2
3
4
5
6
7
SELECT * FROM pg_create_logical_replication_slot('my_slot', 'pgoutput');
+-----------+-----------+
| slot_name | lsn |
|-----------+-----------|
| my_slot | 0/15AF761 |
+-----------+-----------+
|
The returned LSN (log sequence number) is a 64-bit pointer uniquely identifying a location in the WAL, with the first part identifying the WAL segment and the second part identifying the offset within that segment. A consumer subscribing to this slot will receive change events starting from this LSN. |
Unlike text-based decoding plug-ins such as test_decoding, pgoutput emits a binary format, which means that you cannot inspect the messages for a replication slot using Postgres functions such as pg_logical_slot_peek_changes(). To take a quick look at the messages produced by pgoutput on the command line, without running a full CDC solution such as Debezium, you can use my tool pgoutput-cli:
1
2
3
4
5
6
docker run -it --rm --network my-network
gunnarmorling/pgoutput-cli \
pgoutput-cli --host=postgres --port=5432 \
--database=inventorydb --user=dbz_user \
--password=kusnyf-maczuz-7qabnA \
--publication=dbz_publication --slot=my_slot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
{
"op": "I",
"message_id": "b14952a5-4033-4252-a33c-6039f700e9db",
"lsn": 26691112,
"transaction": {
"tx_id": 755,
"begin_lsn": 26691432,
"commit_ts": "2025-07-02T12:09:05.854104Z"
},
"table_schema": {
"column_definitions": [
{
"name": "id",
"part_of_pkey": true,
"type_id": 23,
"type_name": "integer",
"optional": false
},
...
],
"db": "inventorydb",
"schema_name": "inventory",
"table": "customers",
"relation_id": 16391
},
"before": null,
"after": {
"id": 1028,
"first_name": "Sarah",
"last_name": "O'Brian",
"email": "sarah@example.com",
"is_test_account": "f"
}
}
Define a Maximum Replication Slot Size
Replication protocols like Postgres' need to balance keeping transaction logs around long enough so that consumers can catch up after a downtime—for instance during an upgrade, and making sure transaction logs don’t consume an unreasonable amount of disk space on the database machine.
Different systems make different trade-offs in this area. As an example, MySQL allows you to configure a maximum retention time for its binlog; consumers are responsible to process all events from the binlog in time. In contrast, Postgres replication slots require active acknowledgement by the consumer in order to release processed WAL segments. The database will hold onto all the WAL segments for as long as needed for all replication consumers to process the data. Historically, this meant that a replication slot could cause an unlimited amount of WAL backlog if a consumer stopped processing that slot, potentially exhausting the disk space of the database machine when not taking action.
Fortunately, this situation changed with Postgres version 13, which allows you to limit the maximum WAL size a replication slot can hold on to. To do so, specify the max_slot_wal_keep_size parameter in your postgresql.conf file:
1
max_slot_wal_keep_size=50GB
If the difference between a slot’s restart LSN and the current LSN is larger than this limit, the database will invalidate the replication slot and drop older WAL segments. This renders the slot unusable, which means a new slot needs to be created, typically also taking a fresh initial snapshot of the data when using Debezium. While that’s inconvenient for event consumers, it’s definitely preferable to your operational database running out of disk space eventually.
Enable Heartbeats
A situation which is particularly prone to accidental WAL growth is the combination of multiple logical databases with different traffic patterns on one Postgres host. This is because there is one shared WAL for the entire instance, whereas replication slots are scoped to individual databases. Now, imagine a situation where there are many transactions run against one database—thus adding many entries to the WAL—while there’s another database which is idle. A replication slot for that second database can’t make any progress, as it never receives any change events, and therefore will cause more and more WAL segments to be retained.
A solution to this is to produce some "fake" traffic in that second database, allowing its replication slot to progress. Historically, a dedicated heartbeat table was often used for this purpose. However, Postgres 14+ offers an elegant table-less alternative: via the function pg_logical_emit_message(), arbitrary contents can be written to the WAL, without them manifesting in any table. There’s a number of interesting applications for these logical decoding messages, including advancing replication slots in low traffic databases. To enable heartbeat messages with Debezium, add the following to your connector configuration:
1
2
3
4
5
6
{
...
"heartbeat.interval.ms" : "60000",
"heartbeat.action.query" : "SELECT pg_logical_emit_message(false, 'heartbeat', now()::varchar)",
...
}
The connector executes this query every 60 seconds, writing a logical decoding message with the current timestamp to the WAL. Subsequently, it will retrieve the message via logical replication and thus allow the slot to advance. Note that the EXECUTE permission for this function must have been granted to the Debezium database user:
1
2
GRANT EXECUTE ON FUNCTION pg_logical_emit_message(transactional boolean, prefix text, content text)
TO <debezium_user>;
Use Table-level Publications
If you are using the pgoutput logical decoding plug-in, you have fine-grained control over the contents of the replication stream. If you are interested only in changes to ten tables out of 100 tables in your database, streaming changes for exactly those ten tables not only helps with saving resources (CPU, network I/O) on the database side, but it also can drastically reduce egress cost, when streaming change events into another availability zone of your cloud provider.
The pgoutput plug-in relies on Postgres publications for defining which kinds of changes should be published via logical replication. To create a table-level publication, specify all the tables for which change events should be published:
1
CREATE PUBLICATION mypublication FOR TABLE customers, purchase_orders;
If your database has multiple schemas but you only want to capture changes to the tables in a given schema, you can do so by creating publication as follows:
1
CREATE PUBLICATION mypublication FOR TABLES IN SCHEMA inventory;
When using Debezium, it can create publications for you automatically. By default, it will create a publication FOR ALL TABLES. However, this requires superuser permissions and it may unnecessarily stream events of tables which you are going to filter out in the connector anyways.
Alternatively, you can have Debezium create table-level publications by setting the publication.autocreate.mode connector option to filtered. Debezium will then create a publication reflecting the set of captured tables as defined via the connector’s table and schema include/exclude filters. Note that this requires ownership permissions to all affected tables for the connector user.
To follow the principle of least privilege, you should therefore consider creating a publication for the connector by yourself, thus minimizing the set of permissions you need to grant to the connector user. By default, the publication is expected to be named "dbz_publication", but you can override the name via the publication.name connector property. When setting up multiple connectors for capturing distinct sets of tables in the same database, a dedicated publication needs to be created for each connector.
Use Column and Row Filters
As of Postgres 15 and beyond, publications let you further trim down the contents of a replication stream. Via column lists, you can specify which column(s) of a table should be published. This can be very useful to exclude large columns, for instance binary data, which isn’t required for a given use case. Unfortunately, there’s no way to exclude a given column; instead, the names of all columns to be captured need to be specified when creating the publication:
1
2
CREATE PUBLICATION mypublication
FOR TABLE customers (id, first_name, last_name);
If this publication is used via Debezium, make sure that the connector’s column list (as specified via the column.include.list and column.exclude.list connector options), matches the column list of the publication.
Column lists represent a form of projection, i.e. they are akin to the SELECT clause of a SQL query. In addition, publications also provide control over which rows to include in a replication stream via row filters. This corresponds to the WHERE clause of a query, and it is looking very similar to that when creating a publication:
1
2
CREATE PUBLICATION mypublication
FOR TABLE customers WHERE (is_test_account IS FALSE);
Row filters can come in very handy to exclude portions of the operational data set from replication, for example test data or logically deleted data. You can learn more about row filters in this post I wrote after Postgres 15 was released.
When using the snapshotting feature of Debezium—which retrieves rows not via logical replication but by scanning the actual tables in the database—you should specify the same filter expression via the snapshot.select.statement.overrides option in order to ensure consistency between snapshotting and streaming events.
Enable Fail-Over Slots
A long-standing shortcoming of logical replication in Postgres used to be the lack of fail-over support. Until relatively recently, replication slots could only be created on primary instances. If you had set up a Postgres cluster comprising a primary server and a read replica, logical replication couldn’t resume from the replica after promoting it to primary in case of a failure. Instead, you’d typically have to create a new replication slot, which also meant starting with a new initial snapshot if writes could occur on the new primary before creating a new replication slot.
Luckily, over the last few Postgres versions, this issue finally got addressed. In Postgres 16, support for creating replication slots on replicas was added. While not solving the failover problem directly, this is a substantial improvement, as it allows you to have slots on primary and standby servers and manually keep them in sync. To do so, you need to track the progress of the primary slot and move the slot on the stand-by forward accordingly with the help of the pg_replication_slot_advance() function. I wrote about this topic in this post a while ago.
Postgres 17 finally added full support for failover slots. It now can automatically sync the status of a replication slot on a standby server with a slot on the primary, without requiring any manual intervention whatsoever. After failover, consumers can continue to read from the slot on the newly promoted primary, without missing any events, or facing a large amount of duplicate events (some duplicates are to be expected in case the consumer has fetched events from the slot on the primary and a failover happens before the slot state could be updated accordingly on the replica server). To enable failover slots, a bit of configuration is required.
On the primary:
-
Pass
failover=truewhen callingpg_create_logical_replication_slot()for creating the replication slot on the primary; With Debezium 3.0.5 or newer, you can have Debezium create a failover slot by setting theslot.failoverconnector option totrue -
Set the option
synchronized_standby_slotsto the name of the physical slot connecting primary and standby server; this ensures that no logical replication slot can advance beyond the latest LSN synchronized from the primary to the replica
And on the stand-by server:
-
Set the option
sync_replication_slotsto on; this will start a worker process which automatically synchronizes the state of any logical replication slots from the primary server to the stand-by server; alternatively, you can call the functionpg_sync_replication_slots()manually for synchronizing the slot state -
Add the slot’s database name to the connection string used for connecting to the primary server (
primary_conninfo), e.g.…dbname=inventorydb; If you are using Postgres on Amazon RDS, specify the database name instead using the optionrds.logical_slot_sync_dbname -
Set the option
hot_standby_feedbackto true
If you connect to Postgres through a proxy, for instance pgbouncer, promoting a replica to primary can be made fully transparent to your replication consumers such as Debezium, seamlessly continuing to process any change events after a failover. You can find a complete example for doing so in this blog post.
Consider Using Replica Identity FULL
In Postgres, a table’s replica identity determines which fields of a row will be written to the WAL for the old row image for update and delete events. By default, the old value will be only recorded for primary columns. In addition, the value of any TOAST columns will only be contained in the new row image if their value changed.
These peculiarities can make change events somewhat difficult and complex to process for consumers. When performing incremental stream processing on a change event stream, the missing old row image (the before part of Debezium change events), requires a costly state materialization operation. Due to values for unchanged TOAST columns being absent from update events (represented by Debezium with a special value, __debezium_unavailable_value), consumers cannot apply such a change event with simple upsert semantics (I’ve discussed a potential solution for backfilling missing TOAST values via Apache Flink here).
To avoid these problems, consider changing the replica identity of your tables from DEFAULT to FULL:
1
ALTER TABLE inventory.customers REPLICA IDENTITY FULL;
This will cause the complete old and new row image, including TOAST columns, to be written to the WAL and thus be available in data change events. Some Postgres DBAs are concerned about the potential impact on disk utilization and CPU consumption. However, the overhead is actually manageable in many cases. The details depend on your specific workload, so you should do your own benchmarking to measure the exact impact. But as an example, this post mentions a moderate increase of peak CPU consumption from 30% to 35% when enabling replica identity FULL. This should be acceptable in many cases, and doing so can help substantially to simplify the consumption and processing of change event streams.
Monitor, Monitor, Monitor!
Deep observability is key for operating data systems successfully in production. When running Postgres, you should put monitoring and alerting for your replication slots in place to make sure that they’ll never consume unreasonably large amounts of WAL. The following metrics should be constantly tracked using observability tools such as Prometheus and Grafana, Datadog, Elastic, or similar:
-
Total WAL size
-
Retained WAL size per replication slot
-
Remaining WAL space per replication slot
-
Status (active/inactive/invalid) per replication slot
To obtain the total WAL size, you can sum up the sizes of all the files returned by the pg_ls_waldir() function. The slot specific metrics can be retrieved from the pg_replication_slots view, e.g. like so:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
SELECT
slot_name,
plugin,
database,
restart_lsn,
CASE
WHEN invalidation_reason IS NOT NULL THEN 'invalid'
ELSE
CASE
WHEN active IS TRUE THEN 'active'
ELSE 'inactive'
END
END as "status",
pg_size_pretty(
pg_wal_lsn_diff(
pg_current_wal_lsn(), restart_lsn)) AS "retained_wal",
pg_size_pretty(safe_wal_size) AS "safe_wal_size"
FROM
pg_replication_slots
ORDER BY slot_name;
+----------------+----------+-------------+-------------+----------+--------------+---------------+
| slot_name | plugin | database | restart_lsn | status | retained_wal | safe_wal_size |
|----------------+----------+-------------+-------------+----------+--------------+---------------|
| logical_slot_1 | pgoutput | inventorydb | 0/1983A40 | inactive | 2386 MB | 48 GB |
| logical_slot_2 | pgoutput | inventorydb | 0/96BFA970 | active | 3920 bytes | 50 GB |
+----------------+----------+-------------+-------------+----------+--------------+---------------+
The retained WAL size can be calculated by determining the difference between the slot’s restart LSN (the earliest LSN it holds on to) and the current LSN of the database. The safe_wal_size field in the view represents the number of bytes which the slot can hold in addition until it hits the limit configured via max_slot_wal_keep_size (see above).
All these metrics can be obtained from a Postgres instance very easily using the postgres_exporter project, which exposes a Prometheus-compatible endpoint. In addition, it also makes sense to track the remaining free space of the disk or volume holding the WAL. Postgres itself doesn’t expose this value, instead you’ll have to obtain it from your operating system, job orchestrator (such as Kubernetes), or cloud provider (when running Postgres on a service such as Amazon RDS). Last but not least, it is recommended to monitor the MilliSecondsBehindSource metric which Debezium provides for each connector instance. It represents the time it takes from the point in time a change is made in the database until that event is being processed by Debezium. Debezium provides its metrics via JMX; via Prometheus' jmx_exporter component, they can be exposed via HTTP in a Prometheus-compatible format.
As a starting point for your own observability solution for Postgres logical replication slot, you can find a Grafana dashboard displaying most of these metrics here:
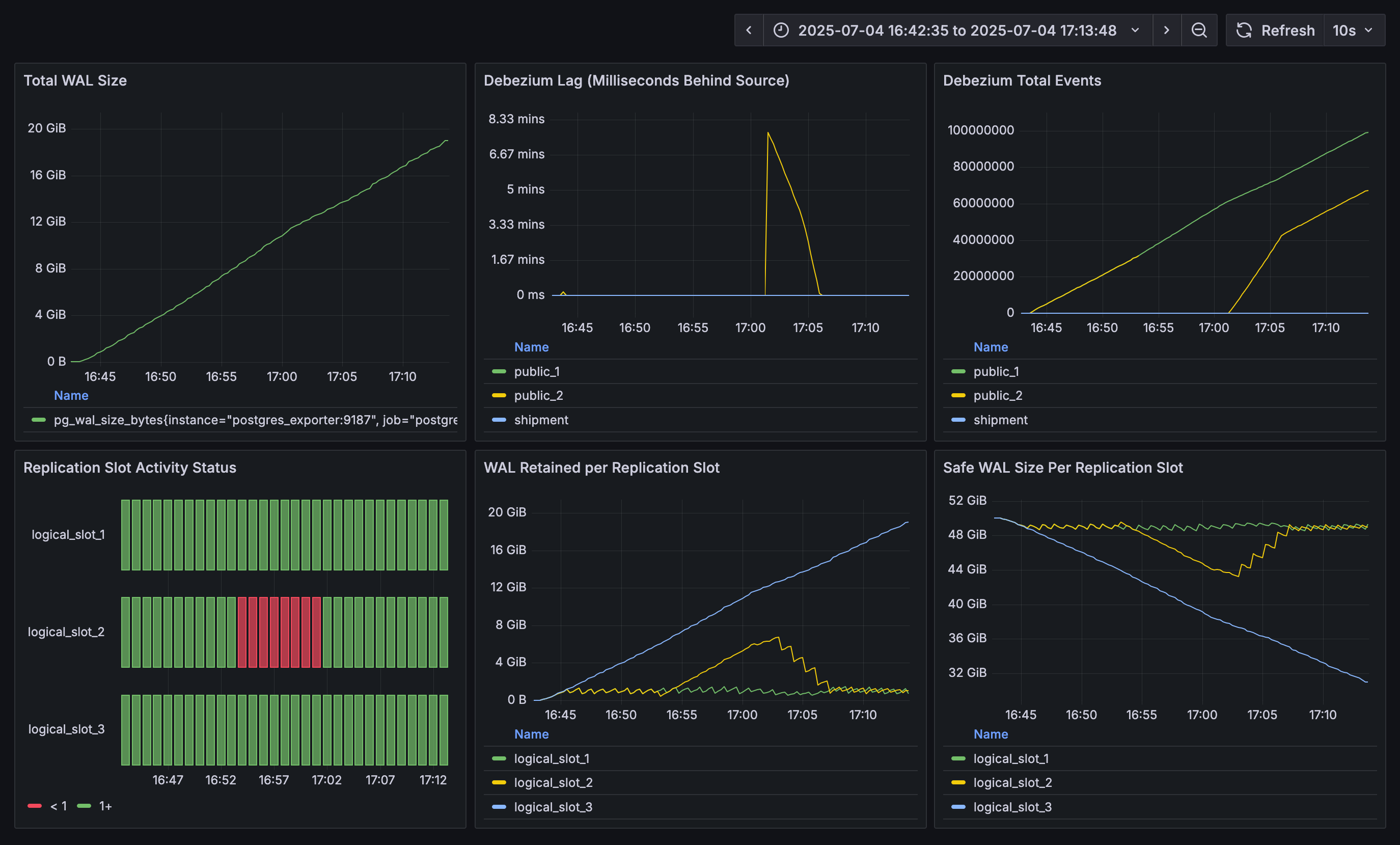
The example shows results from a 30 min run of pgbench (20 connections, four threads each). There are three Debezium connectors with corresponding logical replication slots. Replication slot 1 shows a constant level of WAL retention, as this connector is continuously running and is emitting events. The connector owning slot 2 is stopped for a few minutes in the middle of the run, as indicated by the red columns in the activity status panel. During that time, the WAL backlog of that slot goes up, but it then shrinks again as the connector catches up after being restarted. Slot 3 finally continuously retains more and more WAL, the reason being that this slot is configured against another database on this Postgres host, and no changes are occurring in that database. Thus, Debezium never gets to acknowledge progress on this slot. Heartbeat events, as discussed above, can be used to overcome this situation.
|
What to do if an active replication consumer can’t keep up with the changes in the source database and its replication lag continuously increases? While I am planning to write a separate blog post about tuning the performance of the Debezium Postgres connector, one solution can be to work with multiple replication slots, each exporting changes to a distinct subset of tables, thus allowing you to split the consumer load to multiple processes running on separate machines. To do so, you can copy an existing replication slot with |
Besides visualizing the values in a dashboard, you should also have alerts which trigger when certain thresholds are passed. The specific values depend on your particular database size and the characteristics of your workload. Consider starting with the following values and adjust the thresholds from there to find the right balance between firing early enough and avoiding unnecessary noise:
-
Disk utilization passes 60-70%
-
A replication slot is inactive for longer than 30 minutes
-
A replication slot retains more than 10-20 GB of WAL data
Oftentimes, more than absolute values themselves, the first derivative—i.e. changes to the values—is interesting, and should be subject to alerting, for instance if disk utilization rapidly increases, or if the WAL retained by a replication slot slowly yet steadily grows over a longer period of time.
|
If you apply larger, long-running transactions against your Postgres database, this may cause logical replication to spill state to disk during decoding the WAL contents, increasing the I/O load of the machine and slowing down the replication process. On Postgres 14 and newer, you can examine the disk spill of a replication slot by querying the If you are observing an unduly large amount of disk spill, consider increasing the |
Drop Unused Replication Slots
Finally, a housekeeping tip: don’t forget to delete any unused replication slots! In particular, when stopping and deleting a Debezium connector, its replication slot in Postgres will not automatically be removed. If the slot is not required any more for other connectors or other types of replication consumers, you should drop the slot in order to prevent it from blocking the removal of WAL segments. To do so, call the function pg_drop_replication_slot() like so:
1
SELECT pg_drop_replication_slot('my_replication slot');
Once Postgres 18 has been released (planned for September 2025), the new option idle_replication_slot_timeout will come in handy for that. A time-based counterpart to the aforementioned max_slot_wal_keep_size option, it lets you invalidate replication slots after a configurable period of inactivity. Setting it to a reasonably large value such as 48h or 72h will help to make sure that inactive slots are invalidated in time, preventing them from holding on to more and more WAL segments.
Summary
Logical replication slots are an essential building block for building CDC pipelines with Postgres. While concerns about potential WAL growth sometimes lead to uncertainty and anxiety among users, these fears are largely unnecessary when replication slots are set up and configured correctly.
By carefully configuring aspects like the maximum slot size, fine-grained publications, and heartbeats, you can ensure the stability and performance of your Postgres database and your CDC pipelines. Fail-over slots, as supported since Postgres 17, let you resume replication seamlessly after promoting a stand-by server to primary. Finally, put comprehensive monitoring and alerting in place, to make sure your replication slots behave as intended. The Grafana dashboard shown above can be a starting point for doing so; you can find it in my streaming-examples repository on GitHub. Contributions to this dashboard will be very welcomed!