
Project Loom (JEP 425) is probably amongst the most awaited feature additions to Java ever; its implementation of virtual threads (or "green threads") promises developers the ability to create highly concurrent applications, for instance with hundreds of thousands of open HTTP connections, sticking to the well-known thread-per-request programming model, without having to resort to less familiar and often more complex to use reactive approaches.
Having been in the workings for several years, Loom got merged into the mainline of OpenJDK just recently and is available as a preview feature in the latest Java 19 early access builds. I.e. it’s the perfect time to get your hands onto virtual threads and explore the new feature. In this post I’m going to share an interesting aspect I learned about thread scheduling fairness for CPU-bound workloads running on Loom.
Project Loom
First, some context. The problem with the classic thread-per-request model is that only scales up to a certain point. Threads managed by the operating system are a costly resource, which means you can typically have at most a few thousands of them, but not hundreds of thousands, or even millions. Now, if for instance a web application makes a blocking request to a database, the thread making that request is exactly that, blocked. Of course other threads can be scheduled on the CPU in the meantime, but you cannot have more concurrent requests than threads available to you.
Reactive programming models address this limitation by releasing threads upon blocking operations such as file or network IO, allowing other requests to be processed in the meantime. Once a blocking call has completed, the request in question will be continued, using a thread again. This model makes much more efficient use of the threads resource for IO-bound workloads, unfortunately at the price of a more involved programming model, which doesn’t feel familiar to many developers. Also aspects like debuggability or observability can be more challenging with reactive models, as described in the Loom JEP.
This explains the huge excitement and anticipation of Project Loom within the Java community. Loom introduces a notion of virtual threads which are scheduled onto OS-level carrier threads by the JVM. If application code hits a blocking method, Loom will unmount the virtual thread from its curring carrier, making space for other virtual threads to be scheduled. Virtual threads are cheap and managed by the JVM, i.e. you can have many of them, even millions. The beauty of the model is that developers can stick to the familiar thread-per-request programming model without running into scaling issues due to a limited number of available threads. I highly recommend you to read the JEP of Project Loom, which is very well written and provides much more details and context.
Scheduling
Now how does Loom’s scheduler know that a method is blocking? Turns out, it doesn’t. As I learned from Ron Pressler, the main author of Project Loom, it’s the other way around: blocking methods in the JDK have been adjusted for Loom, so as to release the OS-level carrier thread when being called by a virtual thread:
All blocking in Java is done through the JDK (unless you explicitly call native code). We changed the "leaf" blocking methods in the JDK to block the virtual thread rather than the platform thread. E.g. in all of java.util.concurrent there's just one such method: LockSupport.park
— Ron Pressler (@pressron) May 24, 2022
Ron’s reply triggered a very interesting discussion with Tim Fox (e.g. of Vert.x fame): what happens if code is not IO-bound, but CPU-bound? I.e. if code in a virtual thread runs some heavy calculation without ever calling any of the JDK’s blocking methods, will that virtual thread ever be unmounted?
Perhaps surprisingly, the answer currently is: No. Which means that CPU-bound code will actually behave very differently with virtual threads than with OS-level threads. So let’s take a closer look at that phenomenon with the following example program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class LoomTest {
public static long blackHole;
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newCachedThreadPool();
for(int i = 0; i < 64; i++) {
final Instant start = Instant.now();
final int id = i;
executor.submit(() -> {
BigInteger res = BigInteger.ZERO;
for(int j = 0; j < 100_000_000; j++) {
res = res.add(BigInteger.valueOf(1L));
}
blackHole = res.longValue();
System.out.println(id + ";" +
Duration.between(start, Instant.now()).toMillis());
});
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.HOURS);
}
}
64 threads are started at approximately the same time using a traditional cached thread pool,
i.e. OS-level threads.
Each thread counts to 100M (using BigInteger to make it a bit more CPU-intensive) and then prints out how long it took from scheduling
the thread to the point of its completion.
Here are the results from my Mac Mini M1:
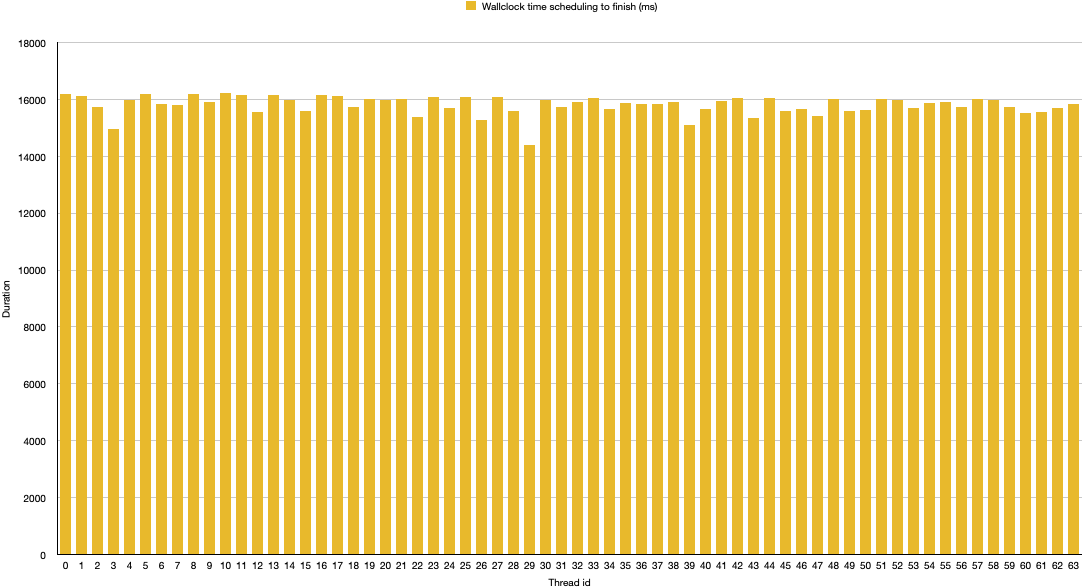
In wallclock time, it took all the 64 threads roughly 16 seconds to complete.
The threads are rather equally scheduled between the available cores of my machine.
I.e. we’re observing a fair scheduling scheme.
Now here are the results using virtual threads (by obtaining the executor via Executors::newVirtualThreadPerTaskExecutor()):
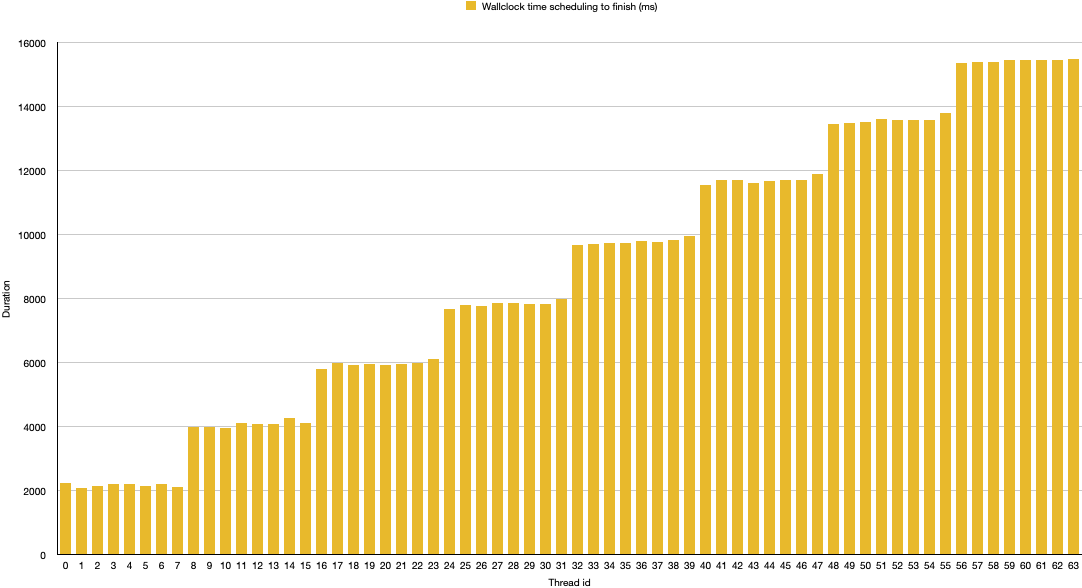
That chart looks very differently. The first eight threads took a wallclock time of about two seconds to complete, the next eight took about four seconds, etc. As the executed code doesn’t hit any of the JDK’s blocking methods, the threads never yield and thus ursurpate their carrier threads until they have run to completion. This represents an unfair scheduling scheme of the threads. While they were all started at the same time, for the first two seconds only eight of them were actually executed, followed by the next eight, and so on.
Loom’s scheduler uses by default as many carrier threads as there are CPU cores available;
There are eight cores in my M1, so processing happens in chunks of eight virtual threads at a time.
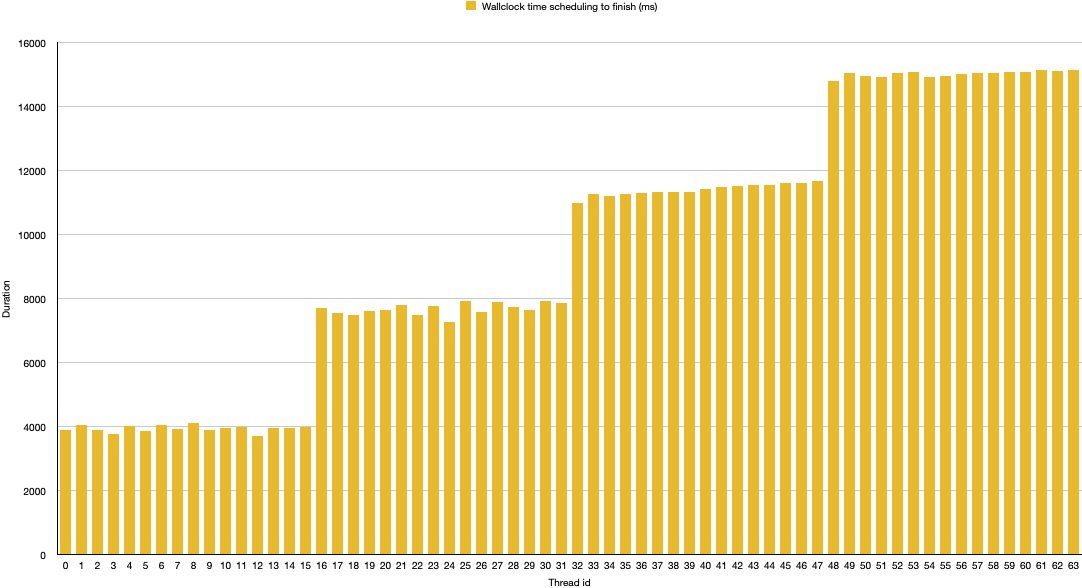
Using the jdk.virtualThreadScheduler.parallelism system property, the number of carrier threads can be adjusted, e.g. to 16:
For the fun of it, let’s add a call to Thread::sleep() (i.e. a blocking method) to the processing loop and see what happens:
1
2
3
4
5
6
7
8
9
10
11
12
13
...
for(int j = 0; j < 100_000_000; j++) {
res = res.add(BigInteger.valueOf(1L));
if (j % 1_000_000 == 0) {
try {
Thread.sleep(1L);
}
catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
...
Surely enough, we’re back to a fair scheduling, with all threads completing after the roughly same wallclock time:
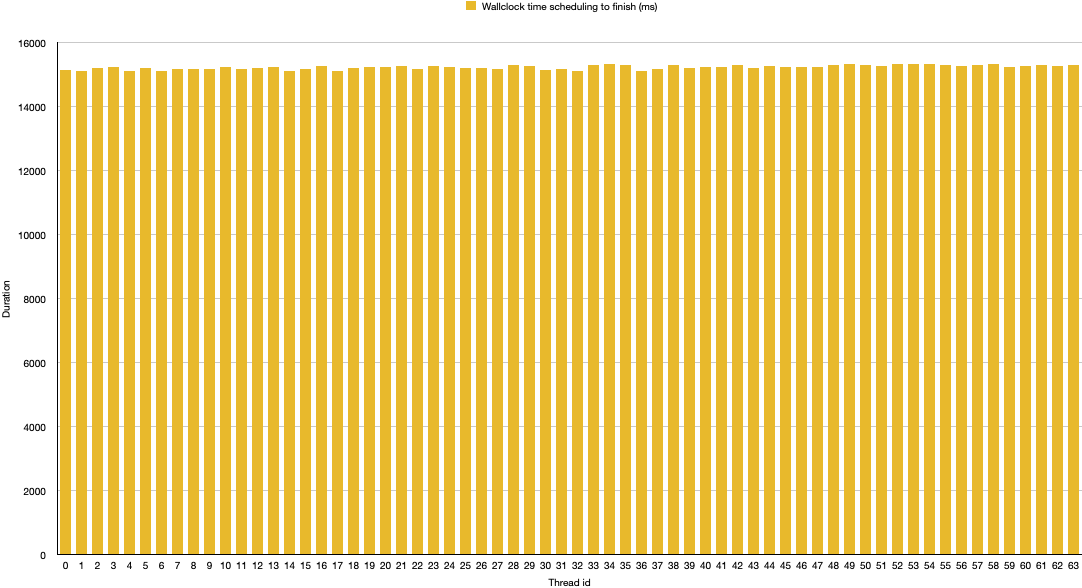
It’s noteworthy that the actual durations appear more harmonized in comparison to the original results we got from running with 64 OS-level threads.
It seems the Loom scheduler can do a slightly better job of distributing the available resources between virtual threads.
Surprisingly, a call to Thread::yield() didn’t have the same result.
While a scheduler is free to ignore this intend to yield as per the method’s JavaDoc,
Sundararajan Athijegannathan indicated that this would be applied by Loom.
It would surely be interesting to know why that’s not the case here.
Discussion
Seeing these results, the big question of course is whether this unfair scheduling of CPU-bound threads in Loom poses a problem in practice or not. Ron and Tim had an expanded debate on that point, which I recommend you to check out to form an opinion yourself. As per Ron, support for yielding at points in program execution other than blocking methods has been implemented in Loom already, but this hasn’t been merged into the mainline with the initial drop of Loom. It should be easy enough though to bring this back if the current behavior turns out to be problematic.
Now there’s not much point in overcommitting to more threads than physically supported by a given CPU anyways for CPU-bound code (nor in using virtual threads to begin with). But in any case it’s worth pointing out that CPU-bound code may behavior differently with virtual threads than with classic OS-level threads. This may come at a suprise for Java developers, in particular if authors of such code are not in charge of selecting the thread executor/scheduler actually used by an application.
Time will tell whether yield support also for CPU-bound code will be required or not,
either via support for explicit calls to Thread::yield() (which I think should be supported at the very least) or through more implicit means, e.g. by yielding when reaching a safepoint.
As I learned, Go’s goroutines support yielding in similar scenarios since version 1.14,
so I wouldn’t be surprised to see Java and Loom taking the same course eventually.