
The JDK Flight Recorder (JFR) is one of Java’s secret weapons; deeply integrated into the Hotspot VM, it’s a high-performance event collection framework, which lets you collect metrics on runtime aspects like object allocation and garbage collection, class loading, file and network I/O, and lock contention, do method profiling, and much more.
JFR data is persisted in recording files (since Java 14, also "realtime" event streaming is supported), which can be loaded for analysis into tools like JDK Mission Control (JMC), or the jfr utility coming with OpenJDK itself.
While there’s lots of blog posts, conference talks, and other coverage on JFR itself, information about the format of recording files is surprisingly heard to come by. There is no official specification, so the only way to actually understand the JFR file format is to read the source code for writing recordings in the JDK itself, which is a combination of Java and C++ code. Alternatively, you can study the code for parsing recordings in JMC (an official JDK project). Btw., JMC comes with a pure Java-based JFR file writer implementation too.
Apart from the source code itself, the only somewhat related resources which I could find are this JavaOne presentation by Staffan Larssan (2013, still referring to the proprietary Oracle JFR), several JFR-related blog posts by Marcus Hirt, and a post about JFR event sizes by Richard Startin. But there’s no in-depth discussion or explanation of the file format. As it turns out, this by design; the OpenJDK team shied away from creating a spec, "because of the overhead of maintaining and staying compatible with it". I.e. the JFR file format is an implementation detail of OpenJDK, and as such the only stable contract for interacting with it are the APIs provided by JFR.
Now, also if it is an implementation detail, knowing more about the JFR file format would certainly be useful; for instance, you could use this to implement tools for analyzing and visualizing JFR data in non-JVM programming languages, say Python, or to patch corrupted recording files. So my curiosity was piqued and I thought it’d be fun to try and find out how JFR recording files are structured. In particular, I was curious about which techniques are used for keeping files relatively small, also with hundreds of thousands or even millions of recoreded events.
I grabbed a hex editor, the source code of JMC’s recording parser
(which I found a bit easier to grasp than the Java/C++ hybrid in the JDK itself),
and loaded several example recordings from my JFR Analytics project,
stepping through the parser code in debug mode
(fun fact: while doing so, I noticed JMC currently fails to parse events with char attributes).
Just a feeew hours later, and I largely understood how the thing works. As an image says more than a thousand words, and I’ll never say no to an opportunity to draw something in the fabuluous Excalidraw, so I proudly present to you this visualization of the JFR file format as per my understanding (click to enlarge):
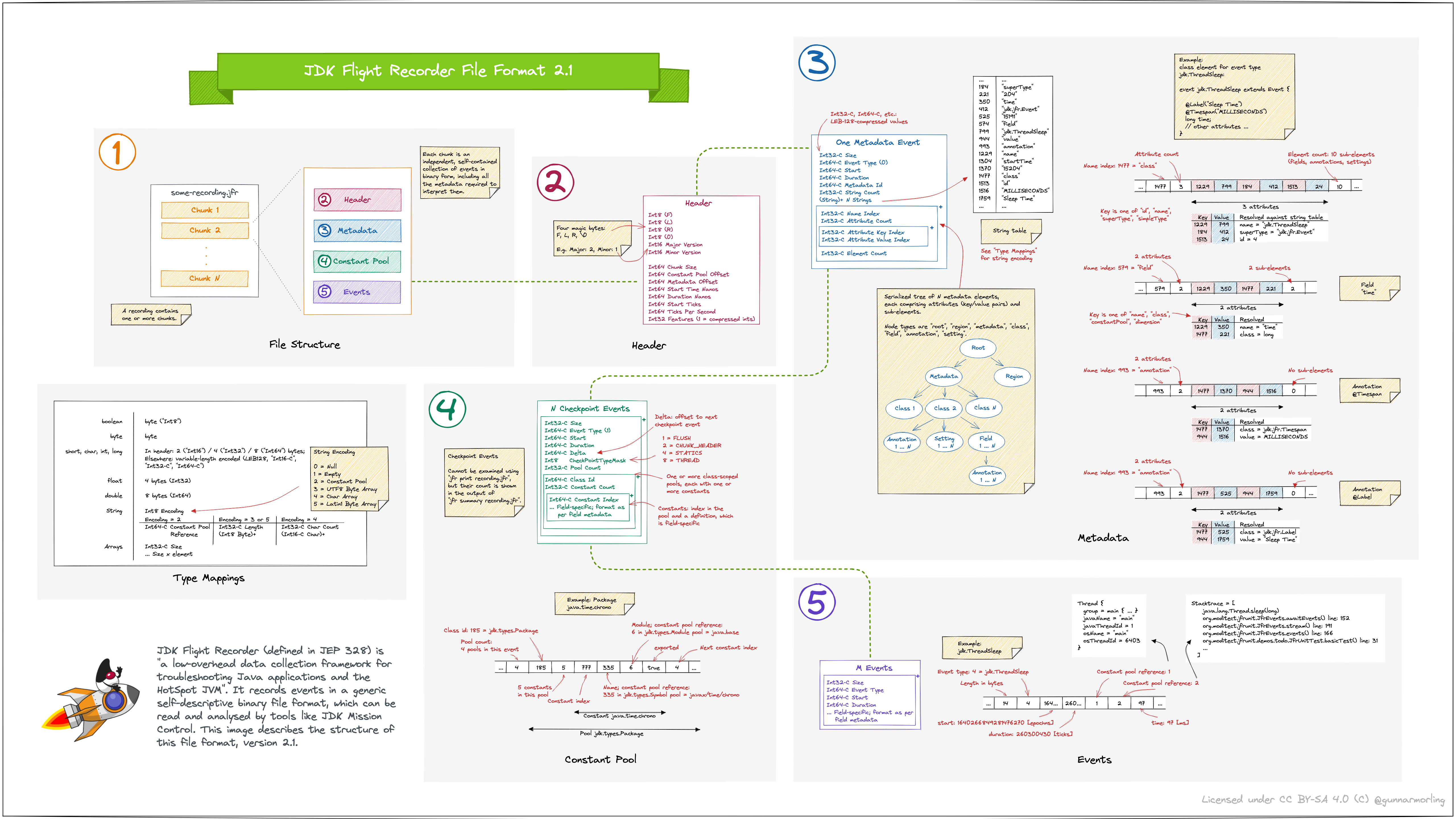
It’s best viewed on a big screen 😎. Alternatively, here’s a SVG version. Now this doesn’t go into all the finest aspects, so you probably couldn’t go off and implement a clean-room JFR file parser solely based on this. But it does show the relevant concepts and mechanisms. I suggest you spend some time going through sections one to five in the picture, and dive into the sections for header, metadata, constant pool, and actual recorded events. Studying the image should give you a good understanding of the JFR file format and its structure.
Here are some observations I made as I found my way through the file format:
-
JFR recordings are organized in chunks: Chunks are self-contained independent containers of recorded events and all the metadata required for interpreting these events. There’s no additional content in recordings besides the chunks, i.e. concat several chunk files, and you’ll have a JFR recording file. A multi-chunk recording file can be split up into the individual chunks using the jfr utility which comes with OpenJDK:
1
jfr disassemble --output <target-dir> some-recording.jfrThe default chunksize is 12MB, but if needed, you can override this, e.g. using the
-XX:FlightRecorderOptions:maxchunksize=1MBoption when starting a recording. A smaller chunk size can come in handy if for instance you only want to transmit a specific section of a long-running recording. On the other hand, many small chunks will increase the overall size of a recording, due to the repeatedly stored metadata and constant pools -
The event format is self-descriptive: The metadata part of each chunk describes the structure of the contained events, all referenced types, their attributes, etc.; by means of JFR metadata annotations, such as
@Label,@Description,@Timestampetc., further metadata like human-readable names and description as well as units of measurements are expressed, allowing to consume and parse an event stream without a-priori knowledge of specific event types. In particular, this allows for the definition of custom event types and displaying them in the generic event browser of JMC (of course, bespoke views such as the "Memory" view rely on type-specific interpretations of individual event types) -
The format is geared towards space efficiency: Integer values are stored in a variable-length encoded way (LEB128), which will safe lots of space when storing small values. A constant pool is used to store repeatedly referenced objects, such as String literals, stack traces, class and method names, etc.; for each usage of such constant in a recorded event, only the constant pool index is stored (a var-length encoded
long). Note that Strings can either be stored as raw values within events themselves, or in the constant pool. Unfortunately, no control is provided for choosing between the two; strings with a length between 16 and 128 will be stored in the constant pool, any others as raw value. It could be a nice extension to give event authors more control here, e.g. by means of an annotation on the event attribute definition
When using the jdk.OldObjectSample event type,
beware of bug JDK-8277919,
which may cause a bloat of the constant pool,
as the same entry is duplicated in the pool many times.
This will be fixed in Java 17.0.3 and 18.
|
-
The format is row-based: Events are stored sequentially one after another in recording files; this means that for instance boolean attributes will consume one full byte, also if actually eight boolean values could be stored in a single byte. It could be interesting to explore a columnar format as an alternative, which may help to further reduce recording size, for instance also allowing to efficiently compress event timestamps values using delta-encoding
-
Compression support in JMC reader implementation: The JFR parser implementation of JMC transparently unpacks recording files which are compressed using GZip, ZIP, or LZ4 (Marcus Hirt discusses the compression of JFR recordings in this post). Interestingly, JMC 8.1 still failed to open such compressed recording with an error message. The jfr utility doesn’t support compressed recording files, and I suppose the JFR writer in the JDK doesn’t produce compressed recordings either