
Hardwood is a new Parquet library for the JVM, written from scratch to do one thing well: read (and soon, write) Apache Parquet files fast, with no mandatory dependencies. It is performance-focused and multi-threaded at its core, fanning page decoding out across all your CPU cores by default.
Today, Hardwood reaches 1.0. After five preview releases since the start of the year (Alpha1, Beta1, Beta2, CR1, CR2), we now consider Hardwood ready for production, and its public API will evolve with a strong focus on backwards compatibility going forward. Hardwood targets Java 21 or newer, is open-source (Apache License 2.0), and is available from Maven Central.
Why Hardwood
Working with the Apache Parquet columnar file format on the JVM has traditionally come with a fairly heavyweight stack: a large number of dependencies on the classpath and a single-threaded reader at the core. Hardwood explores a different set of tradeoffs. The full rationale is in the original project announcement; in a nutshell, the goals are:
-
Implement a Parquet library without any mandatory dependencies:1 Parquet files which are either uncompressed or gzip-compressed don’t require any 3rd party libraries at all; for parsing files compressed with Snappy/Zstd/LZ4/Brotli you only need to provide the (typically single-JAR) codec of your choosing
-
Utilize modern multi-core CPUs as much as possible: unlike parquet-java, which is single-threaded at its core, Hardwood fans out the decoding of the individual pages of a Parquet file to multiple threads, resulting in significantly reduced wall clock parsing times
-
Be compatible: every file which can be parsed by parquet-java should also be parseable with Hardwood; if that’s not the case for a given file, we consider this a bug which needs fixing
What’s in Hardwood 1.0
The 1.0 release implements all the key capabilities you’d expect from a Parquet reader: coverage of all the physical and logical Parquet column types, including VARIANT and a first cut of handling geo-spatial columns, support for all relevant column encodings and compression schemes, the ability to parse both local and remote files (on object storage such as S3), projections and predicate push-down, and much more. The hardwood-examples repository is a great starting point to learn all about Hardwood’s capabilities and how to make the best use of them.
Hardwood comes with two distinct APIs which are at opposite ends of the ergonomics-vs-performance spectrum. The row reader API provides structured access to the records of a Parquet file, including nested and repeatable columns. It’s a great starting point for general-purpose access to Parquet:
try (ParquetFileReader fileReader = ParquetFileReader.open(
InputFile.of(path));
RowReader rowReader = fileReader.rowReader()) {
while (rowReader.hasNext()) {
rowReader.next();
long id = rowReader.getLong("id");
String name = rowReader.getString("name");
LocalDate birthDate = rowReader.getDate("birth_date");
Instant createdAt = rowReader.getTimestamp("created_at");
}
}The column reader API on the other hand exposes a batch-style API for accessing arrays of raw Parquet column values, with a layer scheme inspired by Apache Arrow for representing repeatable columns. It trades ergonomics for throughput: minimal per-value overhead, and batches of primitive arrays the caller can hand straight to a pool of worker threads or a vectorized loop. This makes the column reader the right foundation for analytical workloads over large numbers of values.
While striving to expose exactly one way to achieve a given task generally is a good idea for API design, ergonomics and peak throughput genuinely require different shapes, and we didn’t want to compromise one for the sake of the other. To learn more about the differences between the two reader APIs in Hardwood and when to use which one, refer to this guide on reader models.
Performance
Speaking of performance, let’s take a look at some numbers. Benchmarking Parquet workloads is a wide field; in the following we’re going to touch on two specific workloads.
The first one is a full scan of a flat dataset (i.e. no repeatable or nested columns) of taxi rides in New York City, provided by the NYC Taxi & Limousine Commission. The benchmark folds the values of all 20 columns across twelve files from the dataset, representing the months January to December of 2025. There are 48.7M rows, with a total size of 830 MB compressed.
|
Both benchmarks are implemented using JMH, running five forks with ten measurements each. Benchmarking was done with Java 25 (Temurin build) on an AWS m7i.2xlarge instance (8 vCPU / 4 physical cores; 32 GB of RAM), with the files being served from the operating system’s page cache, i.e. these are microbenchmarks focusing on CPU. To account for variability of the machine’s performance, three runs of the benchmark suite were executed, out of which the results from the median run are shown. Importantly, while absolute throughput varied roughly 10% across runs, the relative ratio between the contenders was stable within ±~3%. The complete source code of the benchmarks and the raw numbers from all runs can be found in this GitHub repository. |
Below are the numbers from processing the taxi rides data with both Hardwood’s column reader and the column API in parquet-java (version 1.17.1). Using all 8 vCPUs, Hardwood achieves a throughput of 16.5M rows/sec. As measuring a multi-threaded engine against a single-threaded one is a bit apples-to-oranges, Hardwood has also been run on a single CPU core, achieving 3.9M rows/sec for this workload.
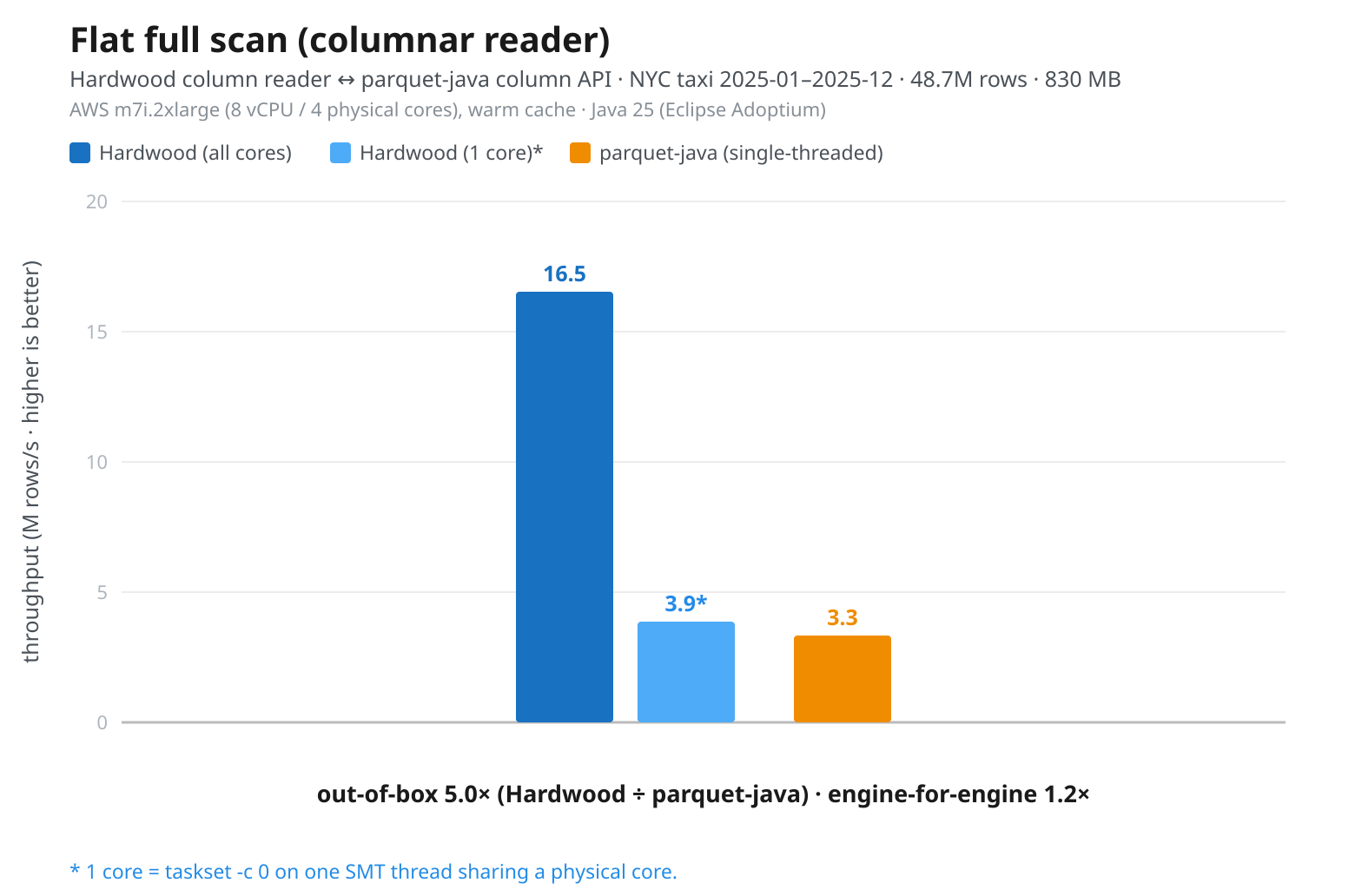
As expected, Hardwood’s advantage here comes from using all the available CPU cores. Even when pinned to a single core (as in, say, a Kubernetes pod with a one-CPU allocation) it held a modest edge over parquet-java on this machine, which makes it a viable option in constrained deployments, too. That single-core margin is small and machine-dependent, though: on other instances we’ve seen it narrow, or tip slightly in parquet-java’s favor. The multi-core advantage, by contrast, was consistent across all our runs.
Next, let’s run the same task with the record-based APIs in both libraries, the row reader API in Hardwood and the Avro reader in parquet-java, materializing Avro’s GenericRecord2:
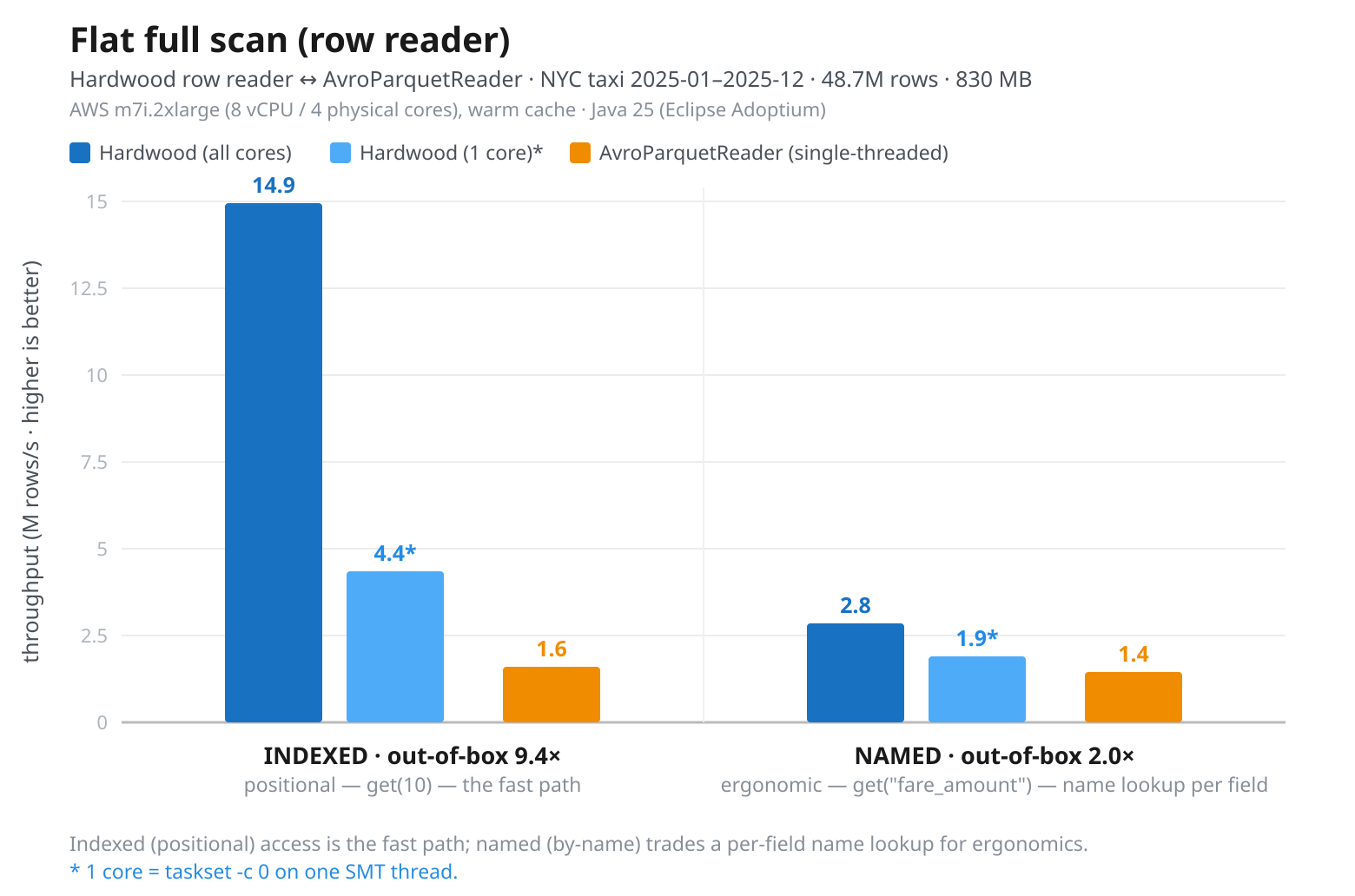
There are a few interesting things worth pointing out. First, Hardwood’s indexed row reader lands within ~10% of the columnar API (14.9 vs 16.5M rows/sec): both feed off the same multi-threaded decode pipeline and differ mainly in how decoded values are surfaced. That being said, once the consumption logic becomes the limiting factor, you could take throughput a step further with the columnar API by fanning out processing to separate worker threads.
Then, there’s a substantial advantage to accessing columns using their projected index instead of via their name. The latter requires a look-up of the column index, for each column of each row. This adds up, so much so that the consumption loop actually becomes the bottleneck, substantially diminishing the advantage of multi-threaded page decoding, with Hardwood only achieving 2.8M rows/sec. So whenever possible, you should hoist the index look-up out of the core reader loop and then work with index-based access.
A key aspect to achieving high throughput when parsing Parquet files is predicate push-down: instead of parsing entire files, the idea is to fetch only those row groups or even pages which match a given query, thus reducing IO (particularly critical when parsing files from object storage) and CPU cycles for decoding. So let’s dive into this use case with a second benchmark. It runs a basic comparison query against a synthetic dataset with 50M rows, filtering on one column, event_time, and projecting another, amount. The visual shows the results from both a selective scenario (the query matches ~5% of rows, clustered in a small number of pages) and the non-selective baseline where all rows match the query:
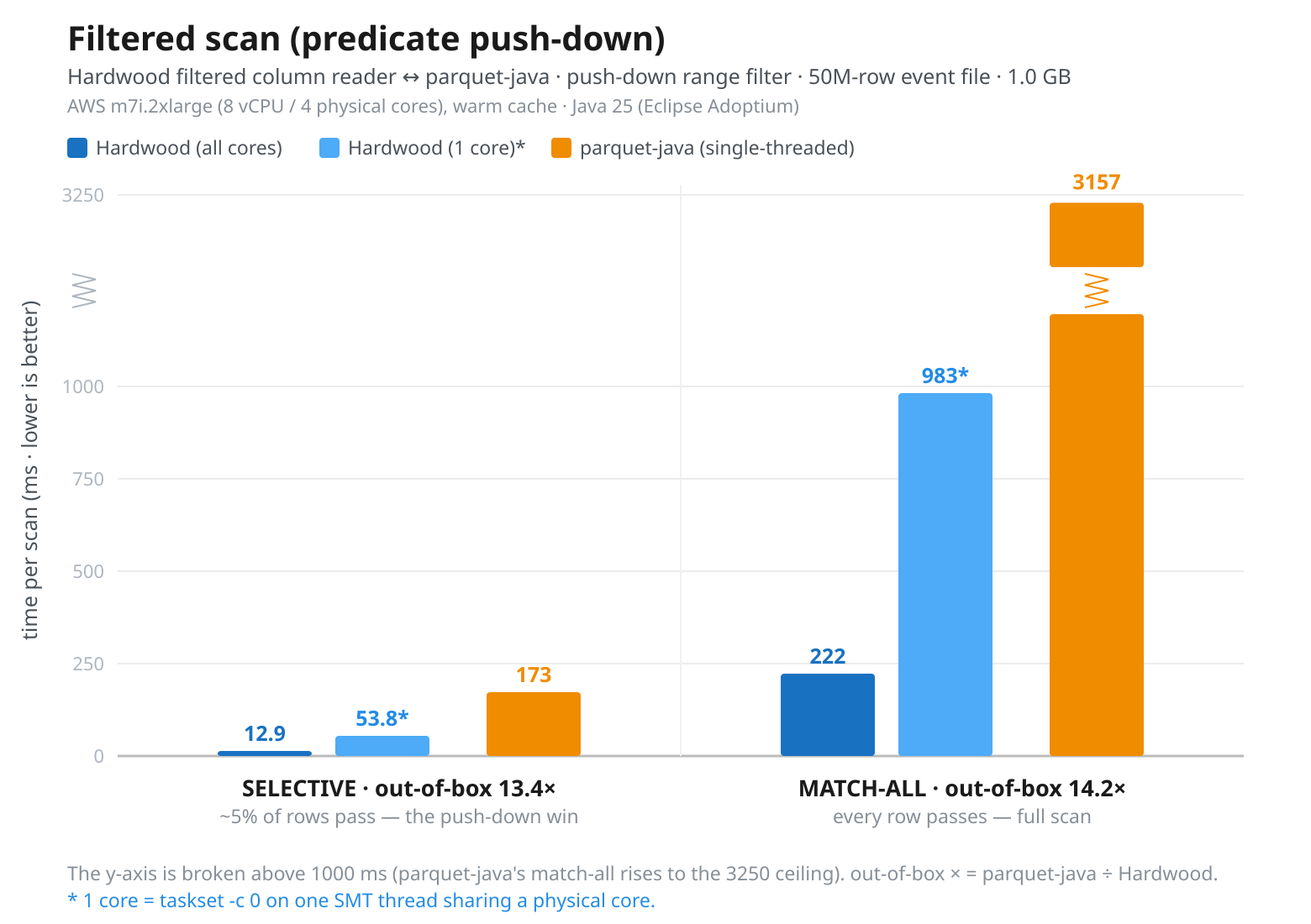
Hardwood performs the selective scan in 12.9 ms on all cores vs. 53.8 ms when pinned to a single vCPU. The match-all scan finishes in 222 ms and 983 ms, respectively. For both Hardwood and parquet-java, execution times scale almost linearly with the ratio of matching results (~17-18x speed-up for returning a result set of 1/20th of the full size), with Hardwood having a substantial and consistent advantage in both cases, benefitting from its branchless, batch-at-a-time predicate evaluation.
Now, you should take these numbers as what they are: a snapshot of the results from running two specific workloads on a specific machine. You should do your own benchmarking with your own files on your own hardware, for your individual access patterns. Start by running the benchmarks discussed, then adjust or extend them as it makes sense. Results depend on a range of factors such as machine specs (how many cores, available SIMD instructions, etc.), local vs. remote access, what kind of queries you are running, what metadata exists in the files, and more. For example, Hardwood doesn’t support Bloom filters yet (it’s under development right now), so if you have an equality predicate on a high cardinality column against a file with Bloom filters, Hardwood wouldn’t run this query optimally yet. That being said, high performance is a key concern for the project which is being worked on continuously, so stay tuned for more.
The Hardwood CLI
Hardwood started life as a JVM library. But as we quickly realized, the same machinery also makes for a handy command-line tool, so we decided to ship it as one too. You can think of the Hardwood CLI as a Swiss-army knife for Parquet files.
It lets you inspect file schemas and metadata such as indexes and dictionaries, you can drill into row groups and column chunks, take a glimpse at the records in a file, export its data to JSON, and much more. The CLI comes with both non-interactive commands, for instance useful for scripting use cases, and an interactive text-based UI (TUI) called hardwood dive, which lets you drill into a file very quickly and intuitively.
If you’d like to give the CLI a shot, you can download native binaries for Linux (aarch64 and x86_64), macOS (aarch64 and x86_64), and Windows (x86_64) from our GitHub release page. No JVM needed, just download the right binary for your platform, and off you go. The following recording shows hardwood dive in action:
Building Open-Source With AI
It’s 2026, so you didn’t think we wouldn’t mention AI at least once in this post, did you? As discussed in the initial project announcement, Hardwood is being built with AI, but not by AI. While I firmly believe we wouldn’t have made progress as quickly without coding agents like Claude Code, we’re generally not vibe coding: every larger change starts from a design doc, the architecture and invariants stay human-owned, and every diff gets read and reviewed before it lands.
As it turns out, Apache Parquet is an excellent fit for this way of LLM-assisted working. It not only provides a comprehensive and well-written specification, it also comes with an extensive test suite in the form of more than 200 Parquet files which we’re using as an executable quality gate for asserting conformance. There are quite a few things to be said about this topic: what works well, what doesn’t, how we go about code reviews, and the one place where we actually do accept a little bit of vibe coding. All of this will get its own post soon. In the meantime, the slides from my recent Hardwood talk at Current London and this InfoQ podcast touch on the approach.
A Big Thank You
Hardwood wouldn’t be anything without the people behind it. Since the project was started in January this year, more than 20 individuals have contributed to the project in the form of pull requests:
Alexei Zenin, André Rouél, Andres Almiray, Arnav Balyan, Brandon Brown, Bruno Borges, Carlos Sousa, Fawzi Essam, Gunnar Morling, Manish, Mohamed Ibrahim Elsawy, muhannd Sayed, Nicolas Grondin, Leo Chashnikov, polo, Prashant Khanal, Rion Williams, Romain Manni-Bucau, Sabarish Rajamohan, Said Boudjelda, Trevin Chow, and Yash Priyadarshan.
Others participated by logging bug reports, asking questions, providing input and feedback, and more. Thanks a lot to all of you! It’s a unique joy to see how a community of like-minded enthusiasts is coming together to build this project.
If you’d like to join the Hardwood community too and do your own first contributions, have a look at the good first issue and help wanted labels in the issue tracker. If you have questions around the project or want to discuss any ideas, then bring them to the Discussion page.
What’s Ahead
The 1.0 Final release is a major milestone for Hardwood; at the same time, we’re really just getting started, and you can look forward to subsequent releases later this year. Most importantly, for Hardwood 1.1, we’re planning to ship initial support for writing Parquet files. This will close a substantial gap, allowing projects with both read and write use cases to adopt Hardwood and benefit from its minimal dependency footprint and multi-threaded execution engine. The exact shape and form of write support for 1.1 is still under discussion, and you’re very much invited to be part of this.
We’re also going to work on a number of performance-related improvements: there’ll be support for Bloom filters as mentioned above, String reuse for dictionary-encoded columns, optimizations around IO when parsing remote files, etc. Other features on the roadmap include support for Parquet encryption, improvements to the TUI, full geo-spatial support, and much more. Besides working on Hardwood itself, we’re also planning to explore integrations with the wider Java data ecosystem; for instance, we’re going to look into building Parquet file support for Apache Flink based on Hardwood.
To get started with using Hardwood, fetch the library from Maven Central (using the dev.hardwood:hardwood-core:1.0.0.Final GAV) or grab the CLI binary for your platform from GitHub Releases. Happy Parquet parsing!