
Exploring ZooKeeper-less Kafka
Sometimes, less is more. One case where that’s certainly true is dependencies. And so it shouldn’t come at a surprise that the Apache Kafka community is eagerly awaiting the removal of the dependency to the ZooKeeper service, which currently is used for storing Kafka metadata (e.g. about topics and partitions) as well as for the purposes of leader election in the cluster.
The Kafka improvement proposal KIP-500 ("Replace ZooKeeper with a Self-Managed Metadata Quorum") promises to make life better for users in many regards:
-
Better getting started and operational experience by requiring to run only one system, Kafka, instead of two
-
Removing potential for discrepancies of metadata state between ZooKeeper and the Kafka controller
-
Simplifying configuration, for instance when it comes to security
-
Better scalability, e.g. in terms of number of partitions; faster execution of operations like topic creation
With KIP-500, Kafka itself will store all the required metadata in an internal Kafka topic, and controller election will be done amongst (a subset of) the Kafka cluster nodes themselves, based on a variant of the Raft protocol for distributed consensus. Removing the ZooKeeper dependency is great not only for running Kafka clusters in production, also for local development and testing being able to start up a Kafka node with a single process comes in very handy.
Having been in the works for multiple years, ZK-less Kafka, also known as KRaft ("Kafka Raft metadata mode"), was recently published as an early access feature with Kafka 2.8. I.e. the perfect time to get my hands on this and get a first feeling for ZK-less Kafka myself. Note this post isn’t meant to be a thorough evaluation or systematic testing of the new Kafka deployment mode, rather take it as a description of how to get started with playing with ZK-less Kafka and of a few observations I made while doing so.
In the world of ZK-less Kafka, there’s two node roles for nodes: controller and broker. Each node in the cluster can have either one or both roles ("combined nodes"). All controller nodes elect the active controller, which is in charge of coordinating the whole cluster, with other controller nodes acting as hot stand-by replicas. In the KRaft KIPs, the active controller sometimes also is simply referred to as leader. This may appear confusing at first, if you are familiar with the existing concept of partition leaders. It started to make sense to me once I realized that the active controller is the leader of the sole partition of the metadata topic. All broker nodes are handling client requests, just as before with ZooKeeper.
While for smaller clusters it is expected that the majority of, or even all cluster nodes act as controllers, you may have dedicated controller-only nodes in larger clusters, e.g. 3 controller nodes and 7 broker nodes in a cluster of 10 nodes overall. As per the KRaft README, having dedicated controller nodes should increase overall stability, as for instance an out-of-memory error on a broker wouldn’t impact controllers, or potentially even cause a leader re-election.
Trying ZK-less Kafka Yourself
As a foundation, I’ve created a variant of the Debezium 1.6 container image, which updates Kafka from 2.7 to Kafka 2.8, and also does the required changes to the entrypoint script for using the KRaft mode. Note this change hasn’t been merged yet to the upstream Debezium repository, so if you’d like to try out things by yourself, you’ll have to clone my repo, and then build the container image yourself like this:
$ git clone git@github.com:gunnarmorling/docker-images.git
$ cd docker-images/kafka/1.6
$ docker build -t debezium/zkless-kafka:1.6 --build-arg DEBEZIUM_VERSION=1.6.0 .In order to start the image with Kafka in KRaft mode, the CLUSTER_ID environment variable must be set.
A value can be obtained using the new bin/kafka-storage.sh script;
going forward, we’ll likely add an option to the Debezium Kafka container image for doing so.
If that variable is set,
the entrypoint script of the image does the following things:
-
Use config/kraft/server.properties instead of config/server.properties as the Kafka configuration file; this one comes with the Kafka distribution and is meant for nodes which should have both the controller and broker roles; i.e. the container image currently only supports combined nodes
-
Format the node’s storage directory, if not the case yet
-
Set up a listener for controller communication
Based on that, here is what’s needed in a Docker Compose file for spinning up a Kafka cluster with three nodes:
version: '2'
services:
kafka-1:
image: debezium/zkless-kafka:1.6
ports:
- 19092:9092
- 19093:9093
environment:
- CLUSTER_ID=oh-sxaDRTcyAr6pFRbXyzA (1)
- BROKER_ID=1 (2)
- KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 (3)
kafka-2:
image: debezium/zkless-kafka:1.6
ports:
- 29092:9092
- 29093:9093
environment:
- CLUSTER_ID=oh-sxaDRTcyAr6pFRbXyzA (1)
- BROKER_ID=2 (2)
- KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 (3)
kafka-3:
image: debezium/zkless-kafka:1.6
ports:
- 39092:9092
- 39093:9093
environment:
- CLUSTER_ID=oh-sxaDRTcyAr6pFRbXyzA (1)
- BROKER_ID=3 (2)
- KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 (3)| 1 | Cluster id; must be the same for all the nodes |
| 2 | Broker id; must be unique for each node |
| 3 | Addresses of all the controller nodes in the format id1@host1:port1,id2@host2:port2… |
No ZooKeeper nodes, yeah :)
Working on Debezium, and being a Kafka Connect aficionado allaround, I’m also going to add Connect and a Postgres database for testing purposes (you can find the complete Compose file here):
version: '2'
services:
# ...
connect:
image: debezium/connect:1.6
ports:
- 8083:8083
links:
- kafka-1
- kafka-2
- kafka-3
- postgres
environment:
- BOOTSTRAP_SERVERS=kafka-1:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
postgres:
image: debezium/example-postgres:1.6
ports:
- 5432:5432
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgresNow let’s start everything:
$ docker-compose -f docker-compose-zkless-kafka.yaml upLet’s also register an instance of the Debezium Postgres connector, which will connect to the PG database and take an initial snapshot, so we got some topics with a few messages to play with:
$ curl -0 -v -X POST http://localhost:8083/connectors \
-H "Expect:" \
-H 'Content-Type: application/json; charset=utf-8' \
--data-binary @- << EOF
{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "dbserver1",
"schema.include": "inventory",
"topic.creation.default.replication.factor": 2,
"topic.creation.default.partitions": 10
}
}
EOFNote how this is using a replication factor of 2 for all the topics created via Kafka Connect, which will come in handy for some experimenting later on.
The nosy person I am, I first wanted to take a look into that new internal metadata topic,
where all the cluster metadata is stored.
As per the release announcement,
it should be named @metadata.
But no such topic shows up when listing the available topics;
only the __consumer_offsets topic, the change data topics created by Debezium, and some Kafka Connect specific topics are shown:
# Get a shell on one of the broker containers
$ docker-compose -f docker-compose-zkless-kafka.yaml exec kafka-1 bash
# In that shell
$ /kafka/bin/kafka-topics.sh --bootstrap-server kafka-3:9092 --list
__consumer_offsets
dbserver1.inventory.customers
dbserver1.inventory.geom
dbserver1.inventory.orders
dbserver1.inventory.products
dbserver1.inventory.products_on_hand
dbserver1.inventory.spatial_ref_sys
my_connect_configs
my_connect_offsets
my_connect_statusesSeems that this topic is truly meant to be internal; also trying to consume messages from the topic with kafka-console-consumer.sh or kafkacat fails due to the invalid topic name. Let’s see whether things are going to change here, since KIP-595 ("A Raft Protocol for the Metadata Quorum") explicitly mentions the ability for consumers to "read the contents of the metadata log for debugging purposes".
In the meantime, we can take a look at the contents of the metadata topic using the kafka-dump-log.sh utility,
e.g. filtering out all RegisterBroker records:
$ /kafka/bin/kafka-dump-log.sh --cluster-metadata-decoder \
--skip-record-metadata \
--files /kafka/data//\@metadata-0/*.log | grep REGISTER_BROKER
payload: {"type":"REGISTER_BROKER_RECORD","version":0,"data":{"brokerId":3,"incarnationId":"O_PiUrjNTsqVEQv61gB2Vg","brokerEpoch":0,"endPoints":[{"name":"PLAINTEXT","host":"172.18.0.2","port":9092,"securityProtocol":0}],"features":[],"rack":null}}
payload: {"type":"REGISTER_BROKER_RECORD","version":0,"data":{"brokerId":1,"incarnationId":"FbOZdz9rSZqTyuSKr12JWg","brokerEpoch":2,"endPoints":[{"name":"PLAINTEXT","host":"172.18.0.3","port":9092,"securityProtocol":0}],"features":[],"rack":null}}
payload: {"type":"REGISTER_BROKER_RECORD","version":0,"data":{"brokerId":2,"incarnationId":"ZF_WQqk_T5q3l1vhiWT_FA","brokerEpoch":4,"endPoints":[{"name":"PLAINTEXT","host":"172.18.0.4","port":9092,"securityProtocol":0}],"features":[],"rack":null}}
...The individual record formats are described in KIP-631 ("The Quorum-based Kafka Controller").
Another approach would be to use a brand-new tool, kafka-metadata-shell.sh. Also defined in KIP-631, this utility script allows to browse a cluster’s metadata, similarly to zookeeper-shell.sh known from earlier releases. For instance, you can list all brokers and get the metadata of the registration of node 1 like this:
$ /kafka/bin/kafka-metadata-shell.sh --snapshot /kafka/data/@metadata-0/00000000000000000000.log
Loading...
Starting...
[ Kafka Metadata Shell ]
>> ls
brokers configs local metadataQuorum topicIds topics
>> ls brokers
1 2 3
>> cd brokers/1
>> cat registration
RegisterBrokerRecord(brokerId=1, incarnationId=TmM_u-_cQ2ChbUy9NZ9wuA, brokerEpoch=265, endPoints=[BrokerEndpoint(name='PLAINTEXT', host='172.18.0.3', port=9092, securityProtocol=0)], features=[], rack=null)
>>Or to display the current leader:
>> cat /metadataQuorum/leader
MetaLogLeader(nodeId=1, epoch=12)Or to show the metadata of a specific topic partition:
>> cat /topics/dbserver1.inventory.customers/0/data
{
"partitionId" : 0,
"topicId" : "8xjqykVRT_WpkqbXHwbeCA",
"replicas" : [ 2, 3 ],
"isr" : [ 2, 3 ],
"removingReplicas" : null,
"addingReplicas" : null,
"leader" : 2,
"leaderEpoch" : 0,
"partitionEpoch" : 0
}
>>Those are just a few of the things you can do with kafka-metadata-shell.sh, and it surely will be an invaluable tool in the box of administrators in the ZK-less era. Another new tool is kafka-cluster.sh, which currently can do two things: displaying the unique id of a cluster, and unregistering a broker. While the former worked for me:
$ /kafka/bin/kafka-cluster.sh cluster-id --bootstrap-server kafka-1:9092
Cluster ID: oh-sxaDRTcyAr6pFRbXyzAThe latter always failed with a NotControllerException, no matter on which node I invoked the command:
$ /kafka/bin/kafka-cluster.sh unregister --bootstrap-server kafka-1:9092 --id 3
[2021-05-15 20:52:54,626] ERROR [AdminClient clientId=adminclient-1] Unregister broker request for broker ID 3 failed: This is not the correct controller for this cluster.It’s not quite clear to me whether I did something wrong, or whether this functionality simply should not be expected to be supported just yet.
The Raft-based metadata quorum also comes with a set of new metrics (described in KIP-595), allowing to retrieve information like the current active controller, role of the node at hand, and more. Here’s a screenshot of the metrics invoked on a non-leader node:
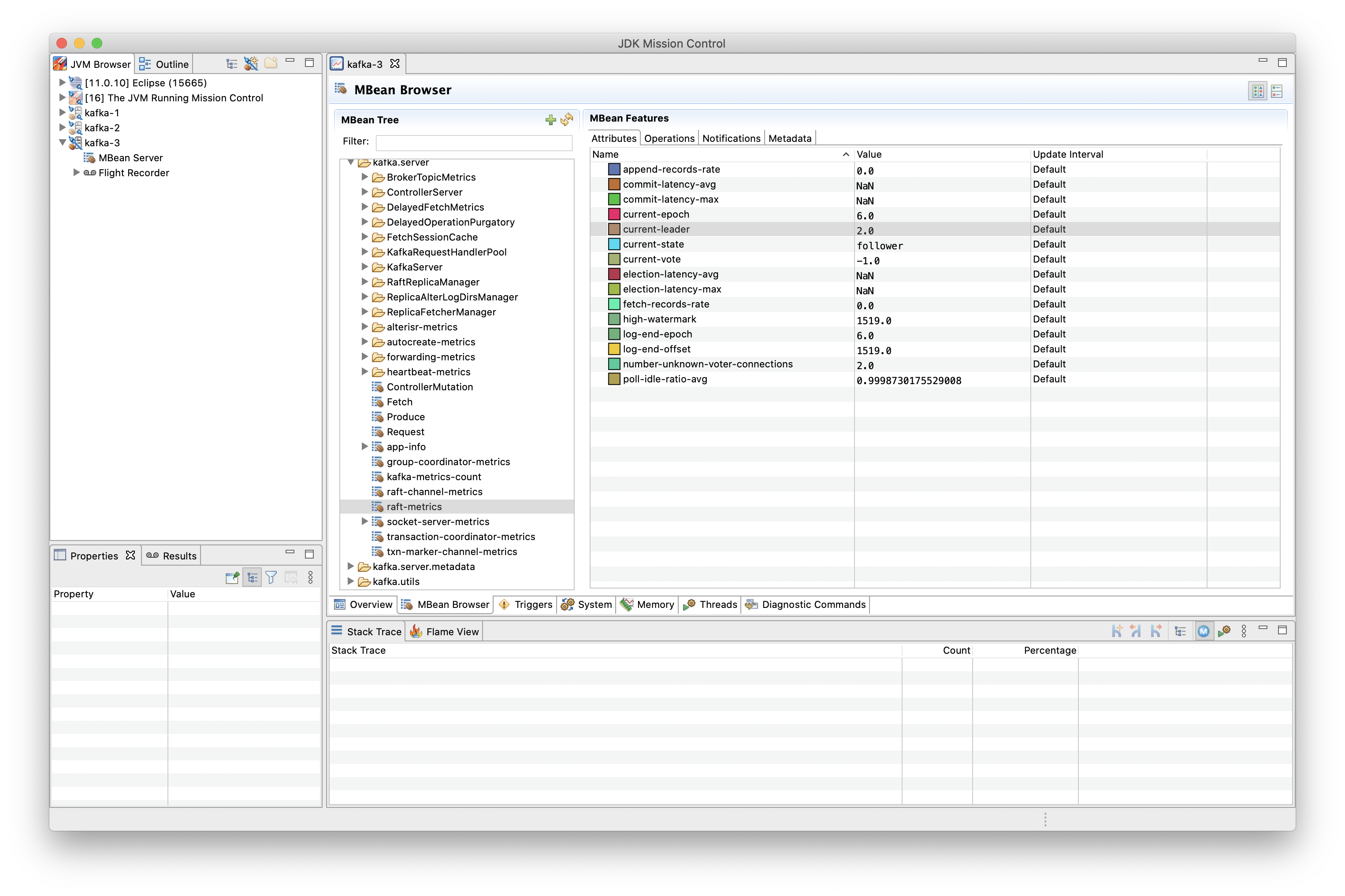
Taking Brokers Down
An essential aspect to any distributed system like Kafka is the fact that invidual nodes of a cluster can disappear at any time, be it due to failures (node crashes, network splits, etc.), or due to controlled shut downs, e.g. for a version upgrade. So I was curious how Kafka in KRaft mode would deal with the situation where nodes in the cluster are stopped and then restarted. Note I’m stopping nodes gracefully via docker-compose stop, instead of randomly crashing them, Jepsen-style ;)
The sequence of events I was testing was the following:
-
Stop the current active controller, so two nodes from the original three-node cluster remain
-
Stop the then new active controller node, at which point the majority of cluster nodes isn’t available any longer
-
Start both nodes again
Here’s a few noteworthy things I observed.
As you’d expect, when stopping the active controller, a new leader was elected (as per the result of cat /metadataQuorum/leader in the Kafka metadata shell),
and also all partitions which had the previous active controller as partition leader, got re-assigned
(in this case node 1 was the active controller and got stopped):
$ /kafka/bin/kafka-topics.sh --bootstrap-server kafka-2:9092 --describe --topic dbserver1.inventory.customers
Topic: dbserver1.inventory.customers TopicId: a6qzjnQwQ2eLNSXL5svW8g PartitionCount: 10 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: dbserver1.inventory.customers Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: dbserver1.inventory.customers Partition: 1 Leader: 1 Replicas: 3,1 Isr: 1,3
Topic: dbserver1.inventory.customers Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: dbserver1.inventory.customers Partition: 3 Leader: 1 Replicas: 2,1 Isr: 1,2
Topic: dbserver1.inventory.customers Partition: 4 Leader: 1 Replicas: 2,1 Isr: 1,2
Topic: dbserver1.inventory.customers Partition: 5 Leader: 2 Replicas: 3,2 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 6 Leader: 2 Replicas: 3,2 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 7 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 8 Leader: 1 Replicas: 2,1 Isr: 1,2
Topic: dbserver1.inventory.customers Partition: 9 Leader: 2 Replicas: 3,2 Isr: 2,3
# After stopping node 1
$ /kafka/bin/kafka-topics.sh --bootstrap-server kafka-2:9092 --describe --topic dbserver1.inventory.customers
Topic: dbserver1.inventory.customers TopicId: a6qzjnQwQ2eLNSXL5svW8g PartitionCount: 10 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: dbserver1.inventory.customers Partition: 0 Leader: 3 Replicas: 1,3 Isr: 3
Topic: dbserver1.inventory.customers Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3
Topic: dbserver1.inventory.customers Partition: 2 Leader: 2 Replicas: 1,2 Isr: 2
Topic: dbserver1.inventory.customers Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2
Topic: dbserver1.inventory.customers Partition: 4 Leader: 2 Replicas: 2,1 Isr: 2
Topic: dbserver1.inventory.customers Partition: 5 Leader: 2 Replicas: 3,2 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 6 Leader: 2 Replicas: 3,2 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 7 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: dbserver1.inventory.customers Partition: 8 Leader: 2 Replicas: 2,1 Isr: 2
Topic: dbserver1.inventory.customers Partition: 9 Leader: 2 Replicas: 3,2 Isr: 2,3Things got interesting though when also stopping the newly elected leader subsequently.
At this point, the cluster isn’t in a healthy state any longer,
as no majority of nodes of the cluster is available for leader election.
Logs of the remaining node are flooded with an UnknownHostException in this situation:
kafka-3_1 | 2021-05-16 10:16:45,282 - WARN [kafka-raft-outbound-request-thread:NetworkClient@992] - [RaftManager nodeId=3] Error connecting to node kafka-2:9093 (id: 2 rack: null)
kafka-3_1 | java.net.UnknownHostException: kafka-2
kafka-3_1 | at java.base/java.net.InetAddress$CachedAddresses.get(InetAddress.java:797)
kafka-3_1 | at java.base/java.net.InetAddress.getAllByName0(InetAddress.java:1505)
kafka-3_1 | at java.base/java.net.InetAddress.getAllByName(InetAddress.java:1364)
kafka-3_1 | at java.base/java.net.InetAddress.getAllByName(InetAddress.java:1298)
kafka-3_1 | at org.apache.kafka.clients.DefaultHostResolver.resolve(DefaultHostResolver.java:27)
kafka-3_1 | at org.apache.kafka.clients.ClientUtils.resolve(ClientUtils.java:111)
kafka-3_1 | at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.currentAddress(ClusterConnectionStates.java:512)
kafka-3_1 | at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.access$200(ClusterConnectionStates.java:466)
kafka-3_1 | at org.apache.kafka.clients.ClusterConnectionStates.currentAddress(ClusterConnectionStates.java:172)
kafka-3_1 | at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:985)
kafka-3_1 | at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:311)
kafka-3_1 | at kafka.common.InterBrokerSendThread.$anonfun$sendRequests$1(InterBrokerSendThread.scala:103)
kafka-3_1 | at kafka.common.InterBrokerSendThread.$anonfun$sendRequests$1$adapted(InterBrokerSendThread.scala:99)
kafka-3_1 | at scala.collection.Iterator.foreach(Iterator.scala:943)
kafka-3_1 | at scala.collection.Iterator.foreach$(Iterator.scala:943)
kafka-3_1 | at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
kafka-3_1 | at scala.collection.IterableLike.foreach(IterableLike.scala:74)
kafka-3_1 | at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
kafka-3_1 | at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
kafka-3_1 | at kafka.common.InterBrokerSendThread.sendRequests(InterBrokerSendThread.scala:99)
kafka-3_1 | at kafka.common.InterBrokerSendThread.pollOnce(InterBrokerSendThread.scala:73)
kafka-3_1 | at kafka.common.InterBrokerSendThread.doWork(InterBrokerSendThread.scala:94)
kafka-3_1 | at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)Here I think it’d be great to get a more explicit indication in the logs of what’s going on, clearly indicating the unhealthy status of the cluster at large.
What’s also interesting is that the remaining node claims to be a leader as per its exposed metrics and value of /metadataQuorum/leader in the metadata shell.
This seems a bit dubious, as no leader election can happen without the majority of nodes available.
Consequently, creation of a topic in this state also times out,
so I suspect this is more an artifact of displaying the cluster state rather than of what’s actually going on.
Things get a bit more troublesome when restarting the two stopped nodes; Very often I’d then see a very high CPU consumption on the Kafka nodes as well as the Connect node:
$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
642eb697fed6 tutorial_connect_1 122.04% 668.3MiB / 7.775GiB 8.39% 99.7MB / 46.9MB 131kB / 106kB 47
5d9806526f92 tutorial_kafka-1_1 9.24% 386.4MiB / 7.775GiB 4.85% 105kB / 104kB 0B / 877kB 93
767e6c0f6cd3 tutorial_kafka-3_1 176.40% 739.2MiB / 7.775GiB 9.28% 14.5MB / 40.6MB 0B / 1.52MB 120
a0ce8438557f tutorial_kafka-2_1 87.51% 567.8MiB / 7.775GiB 7.13% 6.52MB / 24.9MB 0B / 881kB 95
df978d220132 tutorial_postgres_1 0.00% 36.39MiB / 7.775GiB 0.46% 243kB / 5.49MB 0B / 79.4MB 9In some cases stopping and restarting the Kafka nodes would help, other times only a restart of the Connect node would mitigate the situation. I didn’t further explore this issue by taking a thread dump, but I suppose threads are stuck in some kind of busy spin loop at this point. The early access state of KRaft mode seems to be somewhat showing here. After bringing up the issue on the Kafka mailing list, I’ve logged KAFKA-12801 for this problem, as it seems not to have been tracked before.
On the bright side, once all brokers were up and running again, the cluster and the Debezium connector would happily continue their work.
Wrap-Up
Not many features have been awaited by the Kafka community as eagerly as the removal of the ZooKeeper dependency. Rightly so: Kafka-based metadata storage and leader election will greatly simplify the operational burden for running Kafka and also allow for better scalability. Lifting the requirement for running separate ZooKeeper processes or even machines should also help to make things more cost-effective, so you should benefit from this change no matter whether you’re running Kafka yourself or are using a managed service offering.
The early access release of ZK-less Kafka in version 2.8 gives a first impression of what will hopefully be the standard way of running Kafka in the not too distant future. As very clearly stated in the KRaft README, you should not use this in production yet; this matches with the observerations made above: while running Kafka without ZooKeeper definitely feels great, there’s still some rough edges to be sorted out. Also check out the README for a list of currently missing features, such as support of transactions, adding partitions to existing topics, partition reassignment, and more. Lastly, any distributed system should only be fully trusted after going through the grinder of the Jepsen test suite, which I’m sure will only be a question of time.
Despite the early state, I would very much recommend to get started testing ZK-less Kafka at this point, so to get a feeling for it and of course to report back any findings and insights. To do so, either download the upstream Kafka distribution, or build the Debezium 1.6 container image for Kafka with preliminary support for KRaft mode, which lets you set up a ZK-less Kafka cluster in no time.
In order to learn more about ZK-less Kafka, besides diving into the relevant KIPs (which all are linked from the umbrella KIP-500), also check out the QCon talk "Kafka Needs No Keeper" by Colin McCabe, one of the main engineers driving this effort.